2023

Q. Hua P. Grittmann P. Slusallek
Revisiting Controlled Mixture Sampling for Rendering Applications
Publication Type: Article,
ACM Transactions on Graphics (Proceedings of SIGGRAPH 2023), 42(4), 2023
@article{Hua2023,
author = {Hua, Qingqin and Grittmann, Pascal and Slusallek, Philipp},
title = {Revisiting Controlled Mixture Sampling for Rendering Applications},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2023)},
volume = {42},
number = {4},
year = {2023},
month = {jul},
doi = {10.1145/3592435},
publisher = {ACM}
}

M. Kenzel S. Lemme R. Membarth M. Kurtenacker H. Devillers M. Steinberger P. Slusallek
AnyQ: An Evaluation Framework for Massively-Parallel Queue Algorithms
Publication Type: Conference,
Proceedings of the 37th IEEE International Parallel & Distributed Processing Symposium (IPDPS), pp. 736-745, St. Petersburg, FL, USA, May 15-19, 2023
@inproceedings{kenzel2023anyq,
author = {Kenzel, Michael and Lemme, Stefan and Membarth, Richard and Kurtenacker, Matthias and Devillers, Hugo and Steinberger, Markus and Slusallek, Philipp},
address = {St. Petersburg, FL, USA},
title = {{AnyQ}: An Evaluation Framework for Massively-Parallel Queue Algorithms},
booktitle = {Proceedings of the 37th IEEE International Parallel \& Distributed Processing Symposium (IPDPS)},
pages = {736--745},
year = 2023,
month = may,
date = {2023-05-15/2023-05-19},
doi = {10.1109/IPDPS54959.2023.00079},
organization = {IEEE}
}

M. Korać C. Salaün I. Georgiev P. Grittmann P. Slusallek K. Myszkowski G. Singh
Perceptual error optimization for Monte Carlo animation rendering
Publication Type: Article,
ACM SIGGRAPH Asia 2023 Conference Proceedings
@inproceedings{Korac:2023:PerceptualErrorOptimizationAnimation,
author = {Mi\v{s}a Kora\'{c} and Corentin Sala\"{u}n and Iliyan Georgiev and Pascal Grittmann and Philipp Slusallek and Karol Myszkowski and Gurprit Singh},
title = {Perceptual error optimization for Monte Carlo animation rendering},
booktitle = {ACM SIGGRAPH Asia 2023 Conference Proceedings},
year = {2023},
doi = {10.1145/3610548.3618146},
isbn = {979-8-4007-0315-7/23/12}
}

A. Rath Ö. Yazici P. Slusallek
Focal Path Guiding for Light Transport Simulation
Publication Type: Article,
SIGGRAPH '23 Conference Proceedings
@inproceedings{Rath2023,
author = {Rath, Alexander and Yazici, \"{O}mercan and Slusallek, Philipp},
title = {Focal Path Guiding for Light Transport Simulation},
year = {2023},
isbn = {9798400701597},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3588432.3591543},
doi = {10.1145/3588432.3591543},
articleno = {30},
numpages = {10},
}
2022
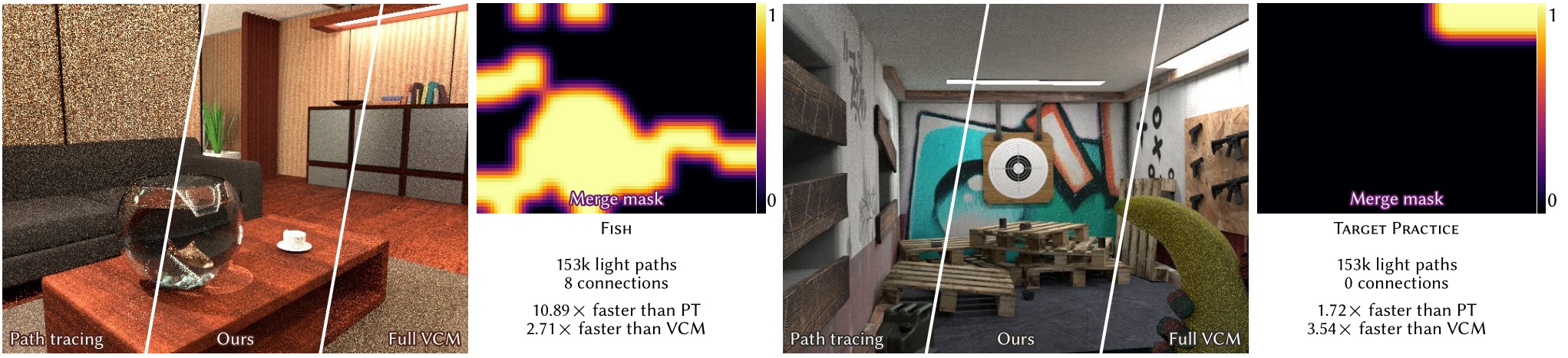
P. Grittmann Ö. Yazici I. Georgiev P. Slusallek
Efficiency-aware multiple importance sampling for bidirectional rendering algorithms
Publication Type: Article,
ACM Transactions on Graphics (Proceedings of SIGGRAPH 2022), 41(4): 80:1-80:12, 2022
@article{Grittmann2022,
author = {Grittmann, Pascal and Yazici, Ömercan and Georgiev, Iliyan and Slusallek, Philipp},
title = {Efficiency-Aware Multiple Importance Sampling for Bidirectional Rendering Algorithms},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2022)},
numpages = {12},
volume = {41},
number = {4},
articleno = {80},
year = {2022},
month = {jul},
doi = {10.1145/3528223.3530126},
publisher = {ACM}
}

Q. Hua V. Tázlar A. Fichet A. Wilkie
Efficient Storage and Importance Sampling for Fluorescent Reflectance
Publication Type: Article,
Computer Graphics Forum, 42(1): 47-59, 2022
@article {Hua2022,
author = {Hua, Qingqin and Tázlar, Vojtěch and Fichet, Alban and Wilkie, Alexander},
title = {{Efficient Storage and Importance Sampling for Fluorescent Reflectance}},
journal = {Computer Graphics Forum},
year = {2023},
editor = {Hauser, Helwig and Alliez, Pierre},
volume = {42},
number = {1},
publisher = {Eurographics ‐ The European Association for Computer Graphics and John Wiley & Sons Ltd.},
pages = {47-59},
DOI = {10.1111/cgf.14716}
}
A. Müller B. Schmidt R. Membarth R. Leißa S. Hack
AnySeq/GPU: A Novel Approach for Faster Sequence Alignment on GPUs
Publication Type: Conference,
Proceedings of the 36th ACM International Conference on Supercomputing (ICS), pp. 20:1-20:11, Virtual Event, June 27-30, 2022
@inproceedings{mueller2022anyseqgpu,
author = {Müller, André and Schmidt, Bertil and Membarth, Richard and Leißa, Roland and Hack, Sebastian},
address = {Virtual Event},
booktitle = {Proceedings of the 36th ACM International Conference on Supercomputing (ICS)},
title = {{AnySeq/GPU}: A Novel Approach for Faster Sequence Alignment on {GPUs}},
pages = {20:1--20:11},
year = 2022,
month = jun,
date = {2022-06-27/2022-06-30},
doi = {10.1145/3524059.3532376},
organization = {ACM}
}

A. Rath P. Grittmann S. Herholz P. Weier P. Slusallek
EARS: Efficiency-Aware Russian Roulette and Splitting
Publication Type: Article,
ACM Transactions on Graphics (Proceedings of SIGGRAPH 2022), 41(4): 81:1-81:14, 2022
@article{Rath2022,
author = {Rath, Alexander and Grittmann, Pascal and Herholz, Sebastian and Weier, Philippe and Slusallek, Philipp},
title = {EARS: Efficiency-Aware Russian Roulette and Splitting},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2022)},
numpages = {14},
volume = {41},
number = {4},
articleno = {81},
year = {2022},
month = {jul},
doi = {10.1145/3528223.3530168},
publisher = {ACM}
}
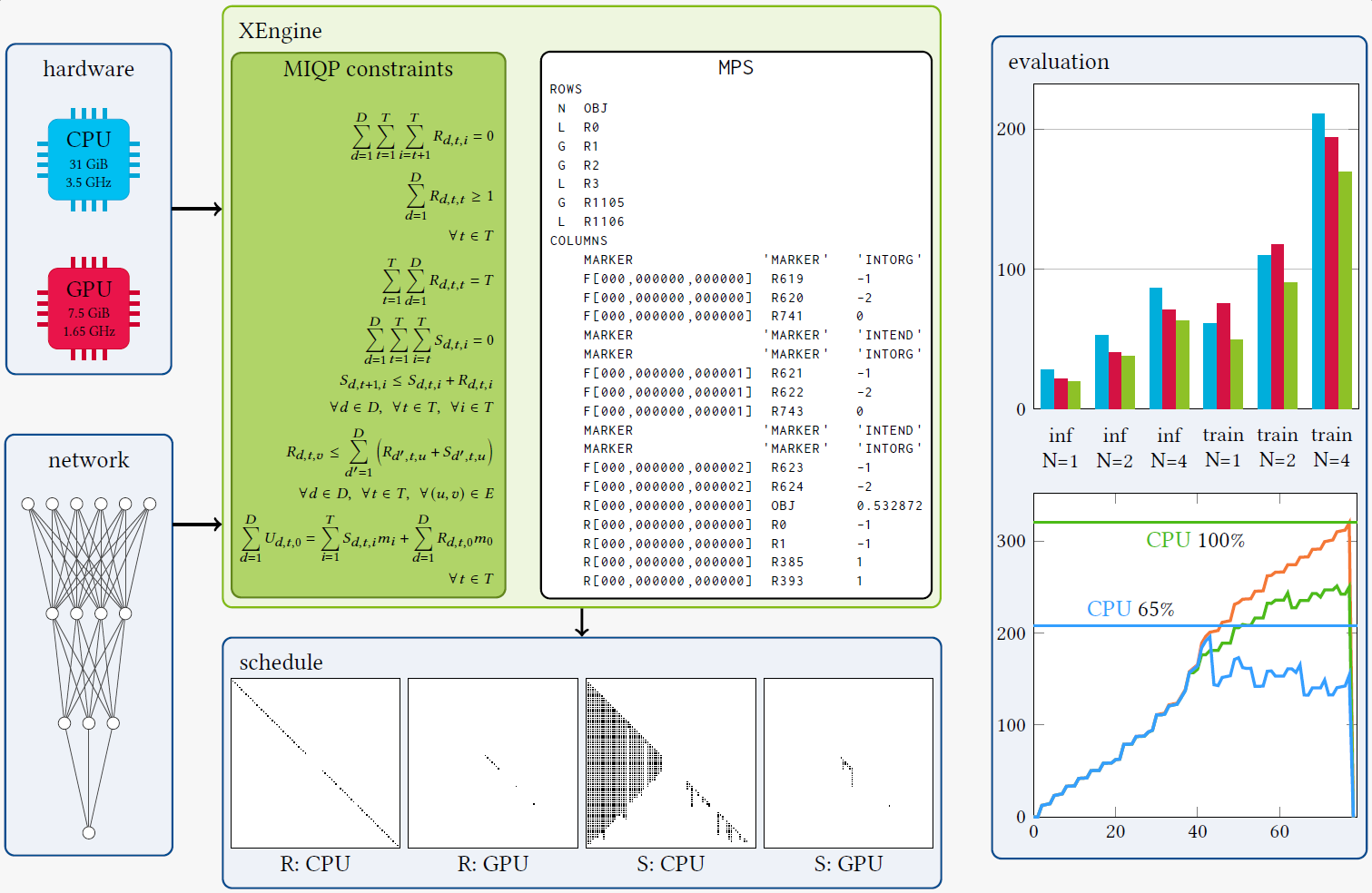
M. Schuler R. Membarth P. Slusallek
XEngine: Optimal Tensor Rematerialization for Neural Networks in Heterogeneous Environments
Publication Type: Article,
ACM Transactions on Architecture and Code Optimization (TACO), 20(1): 17:1-17:25, 2022
@article{schuler2022xengine,
author = {Schuler, Manuela and Membarth, Richard and Slusallek, Philipp},
title = {{XEngine}: Optimal Tensor Rematerialization for Neural Networks in Heterogeneous Environments},
year = {2022},
issue_date = {March 2023},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {20},
number = {1},
issn = {1544-3566},
url = {https://doi.org/10.1145/3568956},
doi = {10.1145/3568956},
journal = {ACM Transactions on Architecture and Code Optimization (TACO)},
month = {dec},
articleno = {17},
numpages = {25},
keywords = {Rematerialization, heterogeneous computing, memory management, neural networks, integer linear programming}
}
X. Xu L. Wang A. Pérard-Gayot R. Membarth C. Li C. Yang P. Slusallek
Temporal Coherence-based Distributed Ray Tracing of Massive Scenes
Publication Type: Article,
IEEE Transactions on Visualization and Computer Graphics (TVCG), 30(2): 1489-1501, 2022
@article{xiang2022distrt,
author = {Xu, Xiang and Wang, Lu and Pérard-Gayot, Arsène and Membarth, Richard and Li, Cuiyu and Yang, Chenglei and Slusallek, Philipp},
title = {Temporal Coherence-Based Distributed Ray Tracing of Massive Scenes},
journal = {IEEE Transactions on Visualization and Computer Graphics (TVCG)},
pages = {1489--1501},
volume = {30},
number = {2},
year = 2022,
month = nov,
date = {2022-11-07},
doi = {10.1109/TVCG.2022.3219982},
publisher = {IEEE}
}
2021
P. Amiri A. Pérard-Gayot R. Membarth P. Slusallek R. Leißa S. Hack
FLOWER: A Comprehensive Dataflow Compiler for High-Level Synthesis
Publication Type: Conference,
Proceedings of the 2021 International Conference on Field-Programmable Technology (FPT), pp. 1-9, Auckland, New Zealand, December 6-10, 2021
@inproceedings{amiri2021flower,
author = {Amiri, Puya and Pérard-Gayot, Arsène and Membarth, Richard and Slusallek, Philipp and Leißa, Roland and Hack, Sebastian},
address = {Auckland, New Zealand},
booktitle = {Proceedings of the 2021 International Conference on Field-Programmable Technology (FPT)},
title = {{FLOWER}: A Comprehensive Dataflow Compiler for High-Level Synthesis},
pages = {1--9},
%year = 2021,
%month = dec,
date = {2021-12-06/2021-12-10},
doi = {10.1109/ICFPT52863.2021.9609930},
organization = {IEEE}
}
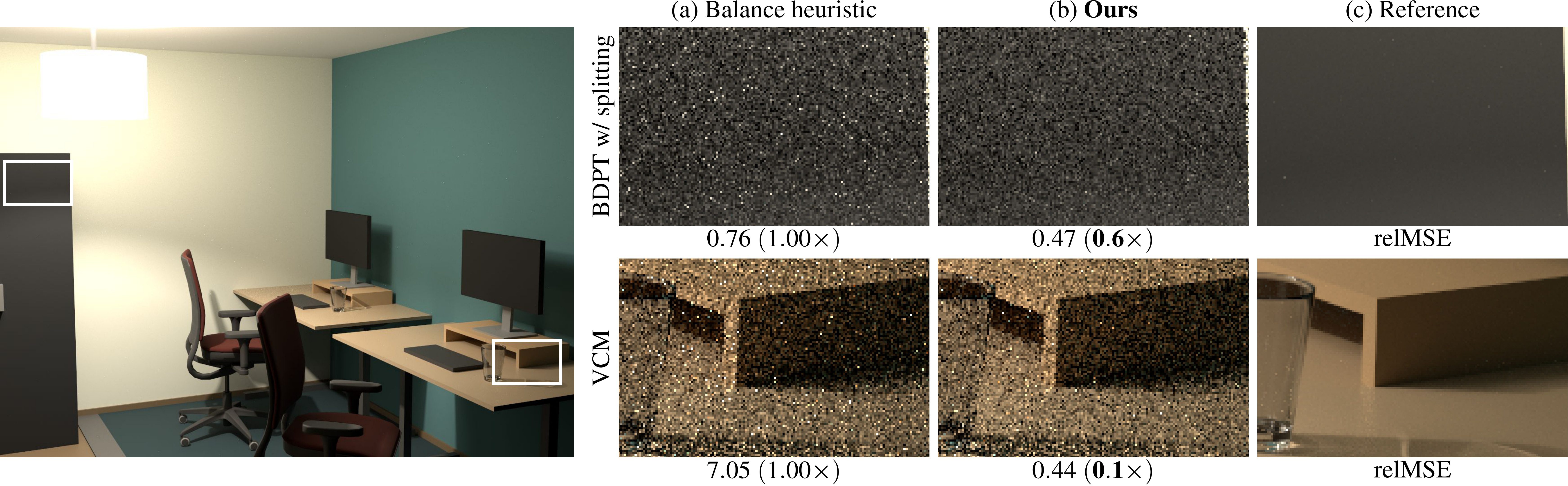
P. Grittmann I. Georgiev P. Slusallek
Correlation-aware multiple importance sampling for bidirectional rendering algorithms
Publication Type: Article,
Computer Graphics Forum (Proceedings of EUROGRAPHICS 2021), 40(2), 2021
@article{Grittmann2021,
author = {Grittmann, Pascal and Georgiev, Iliyan and Slusallek, Philipp},
title = {Correlation-Aware Multiple Importance Sampling for Bidirectional Rendering Algorithms},
journal = {Comput. Graph. Forum (EG 2021)},
volume = {40},
number = {2},
year = 2021
}
R. Ravedutti Lucio Machado J. Schmitt S. Eibl J. Eitzinger R. Leißa S. Hack A. Pérard-Gayot R. Membarth H. Köstler
tinyMD: Mapping Molecular Dynamics Simulations to Heterogeneous Hardware using Partial Evaluation
Publication Type: Article,
Journal of Computational Science (JOCS), 54(101425): 1-11, 2021
@article{ravedutti2021tinymd,
author = {Ravedutti Lucio Machado, Rafael and Schmitt, Jonas and Eibl, Sebastian and Eitzinger, Jan and Leißa, Roland and Hack, Sebastian and Pérard-Gayot, Arsène and Membarth, Richard and Köstler, Harald},
title = {{tinyMD}: Mapping Molecular Dynamics Simulations to Heterogeneous Hardware using Partial Evaluation},
journal = {Journal of Computational Science (JOCS)},
pages = {1--11},
volume = {54},
number = {101425},
year = 2021,
month = jul,
date = {2021-07-10},
doi = {10.1016/j.jocs.2021.101425},
publisher = {Elsevier}
}
2020

A. Keller P. Gautron J. Vorba I. Georgiev M. Šik E. d'Eon P. Grittmann P. Vévoda I. Kondapaneni
Advances in Monte Carlo rendering: The legacy of Jaroslav Křivánek
Publication Type: Course,
@inproceedings{Keller:2020:RenderingCourse,
author = {Keller, Alexander and Grittmann, Pascal and Vorba, Ji\v{r}\'{\i} and Georgiev, Iliyan and \v{S}ik, Martin and d'Eon, Eugene and Gautron, Pascal and V\'{e}voda, Petr and Kondapaneni, Ivo},
title = {Advances in Monte Carlo Rendering: The Legacy of Jaroslav K\v{r}iv\'{a}nek},
year = {2020},
isbn = {9781450379724},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3388769.3407458},
doi = {10.1145/3388769.3407458},
abstract = {Jaroslav K\v{r}iv\'{a}nek's research aimed at finding the one robust and efficient light transport simulation algorithm that would handle any given scene with any complexity of transport. He had a clear and unique vision of how to reach this ambitious goal. On his way, he created an impressive track of significant research contributions. In this course, his collaborators will tell the story of Jaroslav's quest for that "one" algorithm and discuss his impact and legacy.},
booktitle = {ACM SIGGRAPH 2020 Courses},
articleno = {3},
numpages = {366},
location = {Virtual Event, USA},
series = {SIGGRAPH 2020}
}
A. Müller B. Schmidt A. Hildebrandt R. Membarth R. Leißa M. Kruse S. Hack
AnySeq: A High Performance Sequence Alignment Library based on Partial Evaluation
Publication Type: Conference,
Proceedings of the 34th IEEE International Parallel & Distributed Processing Symposium (IPDPS), pp. 1030-1040, New Orleans, LA, USA, May 5-8, 2020
@inproceedings{mueller2020anyseq,
author = {Müller, André and Schmidt, Bertil and Hildebrandt, Andreas and Membarth, Richard and Leißa, Roland and Kruse, Matthis and Hack, Sebastian},
address = {New Orleans, LA, USA},
booktitle = {Proceedings of the 34th IEEE International Parallel \& Distributed Processing Symposium (IPDPS)},
title = {{AnySeq}: A High Performance Sequence Alignment Library based on Partial Evaluation},
pages = {1030--1040},
year = 2020,
month = may,
date = {2020-05-18/2020-05-22},
doi = {10.1109/IPDPS47924.2020.00109},
organization = {IEEE}
}
M. A. Özkan A. Pérard-Gayot R. Membarth P. Slusallek R. Leißa S. Hack J. Teich F. Hannig
AnyHLS: High-Level Synthesis with Partial Evaluation
Publication Type: Article,
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD) (Proceedings of CODES+ISSS 2020), 39(11): 3202-3214, 2020
@article{oezkan2020anyhls,
author = {Özkan, M. Akif and Pérard-Gayot, Arsène and Membarth, Richard and Slusallek, Philipp and Leißa, Roland and Hack, Sebastian and Teich, Jürgen and Hannig, Frank},
title = {{AnyHLS}: High-Level Synthesis with Partial Evaluation},
journal = {IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD) (Proceedings of CODES+ISSS 2020)},
pages = {3202--3214},
volume = {39},
number = {11},
year = 2020,
month = sep,
date = {2020-09-20/2020-09-25},
doi = {10.1109/TCAD.2020.3012172},
publisher = {IEEE}
}

A. Rath P. Grittmann Sebastian Herholz Petr Vévoda P. Slusallek J. Křivánek
Variance-Aware Path Guiding
Publication Type: Article,
ACM Transactions on Graphics (Proceedings of SIGGRAPH 2020), 39(4): 151:1-151:12, 2020
@article{Rath2020,
author = {Rath, Alexander and Grittmann, Pascal and Herholz, Sebastian and V{\'{e}}voda, Petr and Slusallek, Philipp and K{\v{r}}iv{\'{a}}nek, Jaroslav},
title = {Variance-Aware Path Guiding},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2020)},
pages = {151:1--151:12},
volume = {39},
number = {4},
year = 2020,
month = jul,
date = {2020-07-17/2020-07-20},
doi = {10.1145/3386569.3392441},
publisher = {ACM}
}
2019

P. Grittmann I. Georgiev P. Slusallek J. Křivánek
Variance-Aware Multiple Importance Sampling
Publication Type: Article,
ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2019), 38(6): 152:1-152:9, 2019
@article{Grittmann2019,
author = {Grittmann, Pascal and Georgiev, Iliyan and Slusallek, Philipp and K{\v{r}}iv{\'{a}}nek, Jaroslav},
title = {Variance-Aware Multiple Importance Sampling},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2019)},
pages = {152:1--152:9},
volume = {38},
number = {6},
year = 2019,
month = nov,
date = {2019-11-17/2019-11-20},
doi = {10.1145/3355089.3356515},
publisher = {ACM}
}
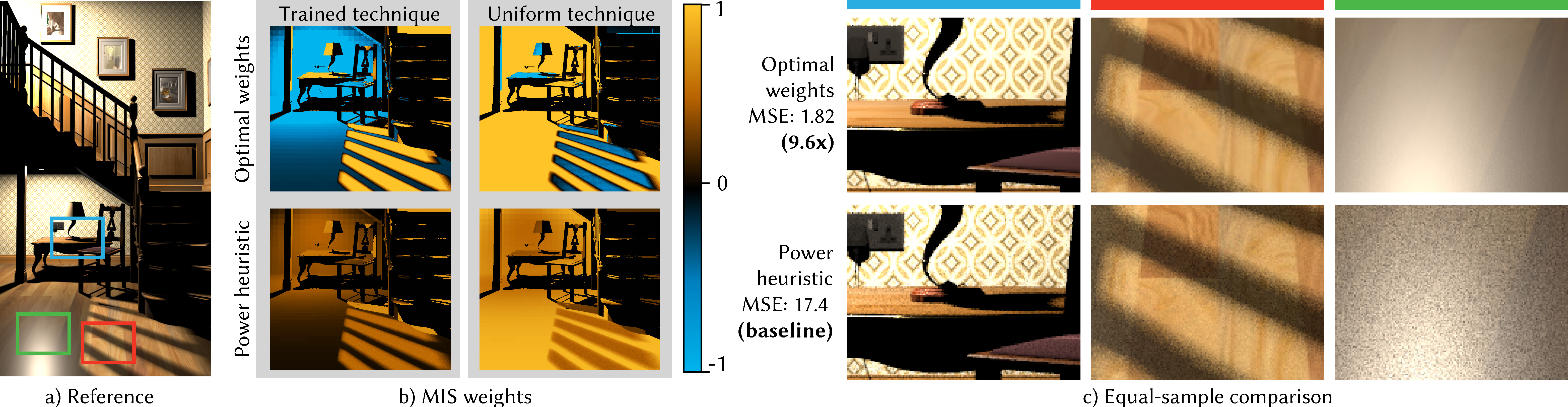
I. Kondapaneni P. Vévoda P. Grittmann T. Skřivan P. Slusallek J. Křivánek
Optimal Multiple Importance Sampling
Publication Type: Article,
ACM Transactions on Graphics (Proceedings of SIGGRAPH 2019), 38(4): 37:1-37:14, 2019
@article{Kondapaneni2019,
author = {Kondapaneni Ivo and V{\'{e}}voda, Petr and Grittmann, Pascal and Sk{\v{r}}ivan, Tom{\'{a}}{\v{s}} and Slusallek, Philipp and K{\v{r}}iv{\'{a}}nek, Jaroslav},
title = {Optimal Multiple Importance Sampling},
journal = {ACM Transactions on Graphics (Proceedings of SIGGRAPH 2019)},
pages = {37:1--37:14},
volume = {38},
number = {4},
year = 2019,
month = jul,
date = {2019-07-28/2019-08-01},
doi = {10.1145/3306346.3323009},
publisher = {ACM}
}
R. Membarth H. Dutta F. Hannig J. Teich
Efficient Mapping of Streaming Applications for Image Processing on Graphics Cards
Publication Type: Article,
Transactions on High-Performance Embedded Architectures and Compilers (Transactions on HiPEAC), V: 1-20, 2019
@article{membarth2019efficientmapping,
author = {Membarth, Richard and Dutta, Hritam and Hannig, Frank and Teich, Jürgen},
title = {Efficient Mapping of Streaming Applications for Image Processing on Graphics Cards},
journal = {Transactions on High-Performance Embedded Architectures and Compilers (Transactions on HiPEAC)},
pages = {1--20},
volume = {V},
%year = 2019,
%month = feb,
date = {2019-02},
doi = {10.1007/978-3-662-58834-5_1},
publisher = {Springer}
}
A. Pérard-Gayot R. Membarth R. Leißa S. Hack P. Slusallek
Rodent: Generating Renderers without Writing a Generator
Publication Type: Article,
ACM Transactions on Graphics (TOG) (Proceedings of SIGGRAPH 2019), 38(4): 40:1-40:12, 2019
@article{perard2019rodent,
author = {Pérard-Gayot, Arsène and Membarth, Richard and Leißa, Roland and Hack, Sebastian and Slusallek, Philipp},
title = {Rodent: Generating Renderers without Writing a Generator},
journal = {ACM Transactions on Graphics (TOG) (Proceedings of SIGGRAPH 2019)},
pages = {40:1--40:12},
volume = {38},
number = {4},
year = 2019,
month = jul,
date = {2019-07-28/2019-08-01},
doi = {10.1145/3306346.3322955},
publisher = {ACM}
}
E. Sánchez Morales R. Membarth A. Gaull P. Slusallek T. Dirndorfer A. Kammenhuber C. Lauer M. Botsch
Parallel Multi-Hypothesis Algorithm for Criticality Estimation in Traffic and Collision Avoidance
Publication Type: Conference,
Proceedings of the 30th IEEE Intelligent Vehicles Symposium (IV), pp. 2164-2171, Paris, France, June 9-12, 2019
@inproceedings{sanchezmorales2019parallelmultihypothesis,
author = {{Sánchez Morales}, Eduardo and Membarth, Richard and Gaull, Andreas and Slusallek, Philipp and Dirndorfer, Tobias and Kammenhuber, Alexander and Lauer, Christoph and Botsch, Michael},
address = {Paris, France},
booktitle = {Proceedings of the 30th IEEE Intelligent Vehicles Symposium (IV)},
title = {Parallel Multi-Hypothesis Algorithm for Criticality Estimation in Traffic and Collision Avoidance},
pages = {2164--2171},
year = 2019,
month = jun,
date = {2019-06-09/2019-06-12},
doi = {10.1109/IVS.2019.8814015},
organization = {IEEE}
}
2018

P. Grittmann A. Pérard-Gayot P. Slusallek J. Krivanek
Efficient Caustic Rendering with Lightweight Photon Mapping
Publication Type: Article,
Computer Graphics Forum (Proceedings of the 29th Eurographics Symposium on Rendering), 37(4): 133-142, 2018
@article {Grittmann:2018:ECR,
author = {Pascal Grittmann and Ars{\`{e}}ne P{\'{e}}rard-Gayot and Philipp Slusallek and Jaroslav K{\v{r}}iv{\'a}nek},
title = {Efficient Caustic Rendering with Lightweight Photon Mapping},
journal = {Computer Graphics Forum},
note = {EGSR~'18},
volume = {37},
number = {4},
issn = {1467-8659},
year = {2018},
}
R. Leißa K. Boesche S. Hack A. Pérard-Gayot R. Membarth P. Slusallek A. Müller B. Schmidt
AnyDSL: A Partial Evaluation Framework for Programming High-Performance Libraries
Publication Type: Article, HiPEAC 2018 Paper Award
Proceedings of the ACM on Programming Languages (PACMPL), 2(OOPSLA): 119:1-119:30, 2018
Proceedings of the ACM on Programming Languages (PACMPL), 2(OOPSLA): 119:1-119:30, 2018
@article{leissa2018anydsl,
author = {Leißa, Roland and Boesche, Klaas and Hack, Sebastian and Pérard-Gayot, Arsène and Membarth, Richard and Slusallek, Philipp and Müller, André and Schmidt, Bertil},
title = {{AnyDSL}: A Partial Evaluation Framework for Programming High-Performance Libraries},
journal = {Proceedings of the ACM on Programming Languages (PACMPL)},
pages = {119:1--119:30},
volume = {2},
number = {OOPSLA},
%year = 2018,
%month = nov,
date = {2018-11-04/2018-11-09},
note = {{HiPEAC 2018 Paper Award}},
doi = {10.1145/3276489},
publisher = {ACM}
}
M. Weier T. Roth A. Hinkenjann P. Slusallek
Foveated Depth-of-Field Filtering in Head-mounted Displays
Publication Type: Conference,
ACM Symposium on Applied Perception (SAP), Vancouver, BC, Canada, August 11-12, 2018
@inproceedings{Weier:2018:FDF:3225153.3243894,
author = {Weier, Martin and Roth, Thorsten and Hinkenjann, Andre and Slusallek, Philipp},
address = {New York, NY, USA},
booktitle = {Proceedings of the 15th ACM Symposium on Applied Perception},
title = {Foveated Depth-of-field Filtering in Head-mounted Displays},
series = {SAP '18},
year = {2018},
isbn = {978-1-4503-5894-1},
location = {Vancouver, British Columbia, Canada},
pages = {18a:1--18a:1},
articleno = {18a},
numpages = {1},
url = {http://doi.acm.org/10.1145/3225153.3243894},
doi = {10.1145/3225153.3243894},
acmid = {3243894},
publisher = {ACM},
address = {New York, NY, USA},
}
M. A. Özkan A. Pérard-Gayot R. Membarth P. Slusallek J. Teich F. Hannig
A Journey into DSL Design using Generative Programming: FPGA Mapping of Image Border Handling through Refinement
Publication Type: Conference,
Proceedings of the Fifth International Workshop on FPGAs for Software Programmers (FSP), pp. 1-9, Dublin, Ireland, August 31, 2018
@inproceedings{oezkan2018fpgaborderhandling,
author = {Özkan, Mehmet Akif and Pérard-Gayot, Arsène and Membarth, Richard and Slusallek, Philipp and Teich, Jürgen and Hannig, Frank},
address = {Dublin, Ireland},
booktitle = {Proceedings of the Fifth International Workshop on FPGAs for Software Programmers (FSP)},
title = {{A Journey into DSL Design using Generative Programming: FPGA Mapping of Image Border Handling through Refinement}},
pages = {1--9},
year = 2018,
month = aug,
date = {2018-08-31},
organization = {VDE}
}
A. Pérard-Gayot R. Membarth P. Slusallek S. Moll R. Leißa S. Hack
A Data Layout Transformation for Vectorizing Compilers
Publication Type: Conference,
Proceedings of the 2018 Workshop on Programming Models for SIMD/Vector Processing (WPMVP), pp. 7:1-7:8, Vösendorf / Vienna, Austria, February 24, 2018
@inproceedings{perard2018splitalloca,
author = {Pérard-Gayot, Arsène and Membarth, Richard and Slusallek, Philipp and Moll, Simon and Leißa, Roland and Hack, Sebastian},
address = {Vösendorf / Vienna, Austria},
booktitle = {Proceedings of the 2018 Workshop on Programming Models for SIMD/Vector Processing (WPMVP)},
title = {{A Data Layout Transformation for Vectorizing Compilers}},
pages = {7:1--7:8},
year = 2018,
month = feb,
date = {2018-02-24},
doi = {10.1145/3178433.3178440},
organization = {ACM}
}
J. Schmitt H. Köstler J. Eitzinger R. Membarth
Unified Code Generation for the Parallel Computation of Pairwise Interactions using Partial Evaluation
Publication Type: Conference,
Proceedings of the 17th International Symposium on Parallel and Distributed Computing (ISPDC), pp. 17-24, Geneva, Switzerland, June 25-28, 2018
@inproceedings{schmitt2018unifiedmd,
author = {Schmitt, Jonas and Köstler, Harald and Eitzinger, Jan and Membarth, Richard},
address = {Geneva, Switzerland},
booktitle = {Proceedings of the 17th International Symposium on Parallel and Distributed Computing (ISPDC)},
title = {{Unified Code Generation for the Parallel Computation of Pairwise Interactions using Partial Evaluation}},
pages = {17--24},
year = 2018,
month = jun,
date = {2018-06-25/2018-06-28},
doi = {10.1109/ISPDC2018.2018.00012},
organization = {IEEE}
}
M. Weier T. Roth A. Hinkenjann P. Slusallek
Foveated Depth-of-Field Filtering in Head-mounted Displays
Publication Type: Inproceedings,
Proceedings of the 15th ACM Symposium on Applied Perception (SAP '18), pp. 18a:1-18a:1
@inproceedings{Weier:2018:FDF:3225153.3243894,
author = {Weier, Martin and Roth, Thorsten and Hinkenjann, Andre and Slusallek, Philipp},
address = {New York, NY, USA},
booktitle = {Proceedings of the 15th ACM Symposium on Applied Perception},
title = {Foveated Depth-of-field Filtering in Head-mounted Displays},
series = {SAP '18},
year = {2018},
isbn = {978-1-4503-5894-1},
location = {Vancouver, British Columbia, Canada},
pages = {18a:1--18a:1},
articleno = {18a},
numpages = {1},
url = {http://doi.acm.org/10.1145/3225153.3243894},
doi = {10.1145/3225153.3243894},
acmid = {3243894},
publisher = {ACM},
address = {New York, NY, USA},
}
2017
A. Kruglova M. Roland S. Diebels T. Dahmen P. Slusallek F. Mücklich
Modelling and characterization of ductile fracture surface in Al-Si alloys by means of Voronoi tessellation
Publication Type: Article,
Materials Characterization, 131: 1-11, 2017
A. Pérard-Gayot J. Kalojanov P. Slusallek
GPU Ray-tracing using Irregular Grids
Publication Type: Article,
Computer Graphics Forum, 36(2): 477-486, 2017
A. Pérard-Gayot M. Weier R. Membarth P. Slusallek R. Leißa S. Hack
RaTrace: Simple and Efficient Abstractions for BVH Ray Traversal Algorithms
Publication Type: Conference,
Proceedings of the 16th ACM SIGPLAN International Conference on Generative Programming: Concepts & Experiences (GPCE), pp. 157-168, Vancouver, BC, Canada, October 23-24, 2017
@inproceedings{perard2017ratrace,
author = {Pérard-Gayot, Arsène and Weier, Martin and Membarth, Richard and Slusallek, Philipp and Leißa, Roland and Hack, Sebastian},
address = {Vancouver, BC, Canada},
booktitle = {Proceedings of the 16th International Conference on Generative Programming: Concepts \& Experiences (GPCE)},
title = {{RaTrace: Simple and Efficient Abstractions for BVH Ray Traversal Algorithms}},
pages = {157--168},
year = 2017,
month = oct,
date = {2017-10-23/2017-10-24},
doi = {10.1145/3136040.3136044},
organization = {ACM}
}
D. Pohl D. Jungmann B. Taudul R. Membarth H. Hariharan T. Herfet O. Grau
The Next Generation of In-home Streaming: Light Fields, 5K, 10 GbE, and Foveated Compression
Publication Type: Conference, Best Paper Award
Proceedings of the 10th International Symposium on Multimedia Applications and Processing (MMAP), pp. 663-667, Prague, Czech Republic, September 3-6, 2017
Proceedings of the 10th International Symposium on Multimedia Applications and Processing (MMAP), pp. 663-667, Prague, Czech Republic, September 3-6, 2017
@inproceedings{pohl2017nextgeneration,
author = {Pohl, Daniel and Jungmann, Daniel and Taudul, Bartosz and Membarth, Richard and Hariharan, Harini and Herfet, Thorsten and Grau, Oliver},
address = {Prague, Czech Republic},
booktitle = {Proceedings of the 10th International Symposium on Multimedia Applications and Processing (MMAP)},
title = {{The Next Generation of In-home Streaming: Light Fields, 5K, 10 GbE, and Foveated Compression}},
pages = {663--667},
year = 2017,
month = sep,
date = {2017-09-03/2017-09-06},
note = {{Best Paper Award}},
doi = {10.15439/2017F16},
organization = {IEEE}
}
O. Reiche M. A. Özkan R. Membarth J. Teich F. Hannig
Generating FPGA-based Image Processing Accelerators with Hipacc
Publication Type: Conference, Invited Paper
Proceedings of the International Conference On Computer Aided Design (ICCAD), pp. 1026-1033, Irvine, CA, USA, November 13-16, 2017
Proceedings of the International Conference On Computer Aided Design (ICCAD), pp. 1026-1033, Irvine, CA, USA, November 13-16, 2017
@inproceedings{reiche2017hipaccfpga,
author = {Reiche, Oliver and Özkan, Mehmet Akif and Membarth, Richard and Teich, Jürgen and Hannig, Frank},
address = {Irvine, CA, USA},
booktitle = {Proceedings of the International Conference On Computer Aided Design (ICCAD)},
title = {{Generating FPGA-based Image Processing Accelerators with Hipacc}},
pages = {1026--1033},
year = 2017,
month = nov,
date = {2017-11-13/2017-11-16},
note = {{Invited Paper}},
doi = {10.1109/ICCAD.2017.8203894},
organization = {IEEE}
}
P. Trampert J. Vogelgesang C. Schorr M. Maisl S. Bogachev N. Marniok A. Louis T. Dahmen P. Slusallek
Spherically symmetric volume elements as basis functions for image reconstructions in computed laminography.
Publication Type: Article,
Journal of X-Ray Science and Technology, 25(4): 533-546, 2017
M. Weier M. Stengel T. Roth P. Didyk E. Eisemann M. Eisemann S. Grogorick A. Hinkenjann E. Krujiff M. Magnor K. Myszkowski P. Slusallek
Perception-driven Accelerated Rendering
Publication Type: Article,
Computer Graphics Forum, 36(2): 611-643, 2017
2016
T. Dahmen N. de Jonge P. Trampert M. Engstler C. Pauly
Smart Microscopy: Feature Based Adaptive Sampling for Focused Ion Beam Scanning Electron Microscopy
Publication Type: Article,
Microscopy and Microanalysis, 22(3): 632-633, 2016
T. Dahmen P. Trampert N. de Jonge P. Slusallek
Advanced recording schemes for electron tomography
Publication Type: Article,
MRS Bulletin, 41(7): 537-541, 2016
T. Dahmen H. Kohr A. Lupini J. Beaudoin C. Kübel P. Trampert P. Slusallek N. de Jonge
Combined Tilt- and Focal-Series Tomography for HAADF-STEM
Publication Type: Article,
Microscopy Today, 24(3): 26-30, 2016
T. Dahmen M. Engstler C. Pauly P. Trampert N. de Jonge F. Mücklich P. Slusallek
Feature Adaptive Sampling for Scanning Electron Microscopy
Publication Type: Article,
Scientific Reports, 6, 2016
F. Einabadi O. Grau
Light Harmonisation for Virtual Production
Publication Type: Inproceedings,
Proceedings of the 13th European Conference on Visual Media Production (CVMP 2016)
P. Grittmann
Implementing a Parallel Renderer with Vertex Connection and Merging
Publication Type: Article,
Bachelor Thesis, Saarland University
J. Kalojanov M. Wand P. Slusallek
Building Construction Sets by Tiling Grammar Simplification
Publication Type: Article,
Computer Graphics Forum, 35(2): 13-25, 2016
S. Lemme J. Sutter C. Schlinkmann P. Slusallek
The Basic Building Blocks of Declarative 3D on the Web
Publication Type: Conference,
Proceedings of the 21st International Conference on Web3D Technology (Web3D '16), pp. 17-25, Anaheim, CA, USA, July 22-24, 2016
D. Limberger W. Scheibel S. Lemme J. Döllner
Dynamic 2.5D Treemaps Using Declarative 3D on the Web
Publication Type: Conference,
Proceedings of the 21st International Conference on Web3D Technology (Web3D '16), pp. 33-36, Anaheim, CA, USA, July 22-24, 2016
R. Membarth O. Reiche F. Hannig J. Teich M. Körner W. Eckert
Hipacc: A Domain-Specific Language and Compiler for Image Processing
Publication Type: Article,
Transactions on Parallel and Distributed Systems (TPDS), 27(1): 210-224, 2016
@article{membarth2016hipacc,
author = {Membarth, Richard and Reiche, Oliver and Hannig, Frank and Teich, Jürgen and Körner, Mario and Eckert, Wieland},
title = {{Hipacc: A Domain-Specific Language and Compiler for Image Processing}},
journal = {Transactions on Parallel and Distributed Systems (TPDS)},
pages = {210--224},
volume = {27},
number = {1},
year = 2016,
month = jan,
date = {2016-01-01},
doi = {10.1109/TPDS.2015.2394802},
publisher = {IEEE},
}
T. Roth M. Weier A. Hinkenjann Y. Li P. Slusallek
An Analysis of Eye-Tracking Data in Foveated Ray Tracing
Publication Type: Inproceedings,
IEEE Second Workshop on Eye Tracking and Visualization (ETVIS), pp. 69-73
P. Trampert D. Chen S. Bogachev T. Dahmen P. Slusallek
Dictionary-based Filling of the Missing Wedge in Electron Tomography
Publication Type: Article,
Microscopy and Microanalysis, 22(3): 554-555, 2016
P. Trampert S. Bogachev T. Dahmen P. Slusallek
A Comparative Study of Three Marker Detection Algorithms in Electron Tomography
Publication Type: Article,
Microscopy and Microanalysis, 22(3): 1044-1045, 2016
B. Turonova L. Marsalek P. Slusallek
On geometric artifacts in cryo electron tomography
Publication Type: Article,
Ultramicroscopy, 163: 48-61, 2016
M. Weier T. Roth E. Krujiff A. Hinkenjann A. Pérard-Gayot P. Slusallek Y. Li
Foveated Real-Time Ray Tracing for Head-Mounted Displays
Publication Type: Conference,
Proceedings of the 24th Pacific Conference on Computer Graphics and Applications (PG '16), pp. 289-298, Okinawa, Japan, October 11-14, 2016
2015
T. Dahmen L. Marsalek N. Marniok B. Turoňová S. Bogachev P. Trampert S. Nickels P. Slusallek
Ettention: building blocks for iterative reconstruction algorithms
Publication Type: Conference,
Proceedings of Microscopy & Microanalysis 2015, Portland, 2.-7. August 2015
T. Dahmen M. Roland T. Tjardes P. Slusallek S. Diebels
An automated workflow for the biomechanical simulation of a tibia with implant using computed tomography and the finite element method
Publication Type: Article,
Computers and Mathematics with Applications
T. Dahmen L. Marsalek N. Marniok B. Turoňová S. Bogachev P. Trampert S. Nickels P. Slusallek
The Ettention software package
Publication Type: Article,
Ultramicroscopy
T. Dahmen H. Kohr N. de Jonge P. Slusallek
Reconstruction Strategies for Combined Tilt- and Focal Series Scanning Transmission Electron Microscopy
Publication Type: Conference,
Proceedings of Microscopy & Microanalysis 2015, Portland, 2.-7. August 2015
T. Dahmen H. Kohr N. de Jonge P. Slusallek
Matched Backprojection Operator for Combined Scanning Transmission Electron Microscopy Tilt- and Focal Series
Publication Type: Article,
Microscopy & Microanalysis
F. Einabadi O. Grau
Discrete Light Source Estimation from Light Probes for Photorealistic Rendering
Publication Type: Inproceedings,
Proceedings of the British Machine Vision Conference (BMVC), pp. 43.1-43.10
I. Killane C. Fearon L. Newman C. McDonnell S. Waechter K. Sons T. Lynch R. B. Reilly
Dual Motor-Cognitive Virtual Reality Training Impacts Dual-Task Performance in Freezing of Gait
Publication Type: Article,
Biomedical and Health Informatics, IEEE Journal of, PP(99): 1-1, 2015
R. Leißa K. Boesche S. Hack R. Membarth P. Slusallek
Shallow Embedding of DSLs via Online Partial Evaluation
Publication Type: Conference, Best Paper Award
Proceedings of the 14th International Conference on Generative Programming: Concepts & Experiences (GPCE), pp. 11-20, Pittsburgh, PA, USA, October 26-27, 2015
Proceedings of the 14th International Conference on Generative Programming: Concepts & Experiences (GPCE), pp. 11-20, Pittsburgh, PA, USA, October 26-27, 2015
@inproceedings{leissa2015shallow,
author = {Leißa, Roland and Boesche, Klaas and Hack, Sebastian and Membarth, Richard and Slusallek, Philipp},
address = {Pittsburgh, PA, USA},
booktitle = {Proceedings of the 14th International Conference on Generative Programming: Concepts \& Experiences (GPCE)},
title = {{Shallow Embedding of DSLs via Online Partial Evaluation}},
pages = {11--20},
year = 2015,
month = oct,
note = {{Best Paper Award}},
date = {2015-10-26/2015-10-27},
doi = {10.1145/2814204.2814208},
organization = {ACM}
}
D. Pohl B. Taudul R. Membarth S. Nickels O. Grau
Advanced In-home Streaming to Mobile Devices and Wearables
Publication Type: Article,
International Journal of Computer Science & Applications (IJCSA), 12(2): 20-36, 2015
@article{pohl2015inhomestreaming,
author = {Pohl, Daniel and Taudul, Bartosz and Membarth, Richard and Nickels, Stefan and Grau, Oliver},
title = {{Advanced In-home Streaming to Mobile Devices and Wearables}},
journal = {International Journal of Computer Science \& Applications (IJCSA)},
pages = {20--36},
volume = {12},
number = {2},
year = 2015,
month = aug,
date = {2015-08},
issn = {0972-9038},
publisher = {Technomathematics Research Foundation},
}
K. Sons F. Klein J. Sutter P. Slusallek
The XML3D Architecture
Publication Type: Poster,
Poster Presentation at
J. Sutter K. Sons P. Slusallek
A CSS Integration Model for Declarative 3D
Publication Type: Inproceedings,
Proceedings of the 20th International Conference on 3D Web Technology (Web3D '15), pp. 209-217
G. Tamm P. Slusallek
Plugin free remote visualization in the browser
Publication Type: Inproceedings,
Visualization and Data Analysis 2015 (Proc. SPIE)
P. Trampert S. Bogachev N. Marniok T. Dahmen P. Slusallek
Marker Detection in Electron Tomography: A Comparative Study
Publication Type: Article,
Microscopy and Microanalysis, 21(6): 1591-1601, 2015
J. Trottnow K. Götz S. Seibert S. Spielmann V. Helzle F. Einabadi C. K. H. Sielaff O. Grau
Intuitive Virtual Production Tools for Set and Light Editing
Publication Type: Inproceedings,
Proceedings of the 12th European Conference on Visual Media Production (CVMP 2015)
B. Turonova L. Marsalek T. Davidovic P. Slusallek
Progressive stochastic reconstruction technique (PSRT): a Monte Carlo approach to 3D reconstruction in cryo electron tomography
Publication Type: Poster,
Poster Presentation at
B. Turonova L. Marsalek T. Davidovic P. Slusallek
PSRT: Progressive Stochastic Reconstruction Technique for Cryo Electron Tomography
Publication Type: Conference,
Proceedings of Microscopy & Microanalysis 2015, Portland, Oregon, 2. - 6. August 2015
B. Turonova L. Marsalek T. Davidovic P. Slusallek
On a novel approach to 3D reconstruction in Cryo Electron Tomography: Progressive Stochastic Reconstruction Technique (PSRT)
Publication Type: Conference,
14. French Microscopy Congress, Nice, France, 30.6. - 3.7.2015, Nice, France, 30.6. - 3.7.2015
B. Turonova L. Marsalek T. Davidovic P. Slusallek
Progressive Stochastic Reconstruction Technique (PSRT) for Cryo Electron Tomography
Publication Type: Article,
Journal of Structural Biology, 189(3): 195-206, 2015
2014
T. Dahmen J. P. Baudoin A. Lupini C. Kuebel P. Slusallek N. de Jonge
Combined tilt- and focal series scanning transmission electron microscopy: TFS 3D STEM
Publication Type: Conference,
Proceedings of 18th International Microscopy Congress, Prague, September, 2014
T. Dahmen J. Baudoin A. Lupini C. Kübel P. Slusallek N. de Jonge
Combined Scanning Transmission Electron Microscopy Tilt- and Focal Series
Publication Type: Article,
Microscopy and Microanalysis
T. Dahmen P. Slusallek N. de Jonge
TFS: Combined Tilt- and Focal Series for Scanning Transmission Electron Microscopy.
Publication Type: Conference,
Proceedings of Microscopy & Microanalysis 2014, Hartford, CA, September, 2014
P. Danilewski M. Köster R. Leißa R. Membarth P. Slusallek
Specialization through Dynamic Staging
Publication Type: Conference,
Proceedings of the 13th International Conference on Generative Programming: Concepts & Experiences (GPCE), pp. 103-112, Västerås, Sweden, September 15-16, 2014
@inproceedings{danilewski2014specialization,
author = {Danilewski, Piotr and Köster, Marcel and Leißa, Roland and Membarth, Richard and Slusallek, Philipp},
address = {Västerås, Sweden},
booktitle = {Proceedings of the 13th International Conference on Generative Programming: Concepts \& Experiences (GPCE)},
title = {{Specialization through Dynamic Staging}},
pages = {103--112},
year = 2014,
month = sep,
date = {2014-09-15/2014-09-16},
}
T. Davidovic J. Krivanek M. Hasan P. Slusallek
Progressive Light Transport Simulation on the GPU: Survey and Improvements
Publication Type: Article,
ACM Transactions on Graphics (TOG), 33(3): 29:1-29:19, 2014
F. Klein T. Spieldenner K. Sons P. Slusallek
Configurable Instances of 3D Models for Declarative 3D in the Web
Publication Type: Inproceedings,
Proceedings of the Nineteenth International ACM Conference on 3D Web Technologies, pp. 71-79
M. Köster R. Leißa S. Hack R. Membarth P. Slusallek
Platform-Specific Optimization and Mapping of Stencil Codes through Refinement
Publication Type: Conference,
Proceedings of the 1st International Workshop on High-Performance Stencil Computations (HiStencils), pp. 1-6, Vienna, Austria, January 21, 2014
@inproceedings{koester2014platformhistencils,
author = {Köster, Marcel and Leißa, Roland and Hack, Sebastian and Membarth, Richard and Slusallek, Philipp},
address = {Vienna, Austria},
booktitle = {Proceedings of the 1st International Workshop on High-Performance Stencil Computations (HiStencils)},
title = {{Platform-Specific Optimization and Mapping of Stencil Codes through Refinement}},
pages = {1--6},
date = {2014-01-21},
}
M. Köster R. Leißa S. Hack R. Membarth P. Slusallek
Code Refinement of Stencil Codes
Publication Type: Article,
Parallel Processing Letters (PPL), 24(3): 1-16, 2014
@article{koester2014platformppl,
author = {Köster, Marcel and Leißa, Roland and Hack, Sebastian and Membarth, Richard and Slusallek, Philipp},
title = {{Code Refinement of Stencil Codes}},
journal = {Parallel Processing Letters (PPL)},
pages = {1--16},
volume = {24},
number = {3},
year = 2014,
month = sep,
date = {2014-09},
doi = {10.1142/S0129626414410035},
publisher = {World Scientific}
}
M. Maisl L. Marsalek C. Schorr J. Horacek P. Slusallek
GPU-accelerated computed laminography with application to non-destructive testing
Publication Type: Inproceedings,
11th European Conference on Non-Destructive Testing (ECNDT 2014)
R. Membarth O. Reiche F. Hannig J. Teich
Code Generation for Embedded Heterogeneous Architectures on Android
Publication Type: Conference,
Proceedings of the Conference on Design, Automation and Test in Europe (DATE), pp. 86:1-86:6, Dresden, Germany, March 24-28, 2014
@inproceedings{membarth2014android,
author = {Membarth, Richard and Reiche, Oliver and Hannig, Frank and Teich, Jürgen},
address = {Dresden, Germany},
booktitle = {Proceedings of the Conference on Design, Automation and Test in Europe (DATE)},
title = {{Code Generation for Embedded Heterogeneous Architectures on Android}},
pages = {86:1--86:6},
year = 2014,
month = mar,
date = {2014-03-24/2014-03-28},
doi = {10.7873/DATE.2014.099},
organization = {IEEE}
}
R. Membarth P. Slusallek M. Köster R. Leißa S. Hack
High-Performance Domain-Specific Languages for GPU Computing
Publication Type: Poster,
Poster Presentation at GPU Technology Conference (GTC), San Jose, CA, USA, March 24-27, 2014
R. Membarth O. Reiche C. Schmitt F. Hannig J. Teich M. Stürmer H. Köstler
Towards a Performance-portable Description of Geometric Multigrid Algorithms using a Domain-specific Language
Publication Type: Article,
Journal of Parallel and Distributed Computing (JPDC), 24(12): 3191-3201, 2014
@article{membarth2014towards,
author = {Membarth, Richard and Reiche, Oliver and Schmitt, Christian and Hannig, Frank and Teich, Jürgen and Stürmer, Markus and Köstler, Harald},
title = {{Towards a Performance-portable Description of Geometric Multigrid Algorithms using a Domain-specific Language}},
journal = {Journal of Parallel and Distributed Computing (JPDC)},
pages = {3191--3201},
volume = {74},
number = {12},
year = 2014,
month = dec,
date = {2014-12},
doi = {10.1016/j.jpdc.2014.08.008},
publisher = {Elsevier}
}
R. Membarth P. Slusallek M. Köster R. Leißa S. Hack
Target-Specific Refinement of Multigrid Codes
Publication Type: Conference,
Proceedings of the 4th International Workshop on Domain-Specific Languages and High-Level Frameworks for High Performance Computing (WOLFHPC), pp. 52-57, New Orleans, LA, USA, November 17, 2014
@inproceedings{membarth2014refinement,
author = {Membarth, Richard and Slusallek, Philipp and Köster, Marcel and Leißa, Roland and Hack, Sebastian},
address = {New Orleans, LA, USA},
booktitle = {Proceedings of the 4th International Workshop on Domain-Specific Languages and High-Level Frameworks for High Performance Computing (WOLFHPC)},
title = {{Target-Specific Refinement of Multigrid Codes}},
pages = {52--57},
year = 2014,
month = nov,
date = {2014-11-17},
doi = {10.1109/WOLFHPC.2014.5},
organization = {IEEE}
}
O. Reiche M. Schmid F. Hannig R. Membarth J. Teich
Code Generation from a Domain-specific Language for C-based HLS of Hardware Accelerators
Publication Type: Conference,
Proceedings of the International Conference on Hardware/Software Codesign and System Synthesis (CODES+ISSS), pp. 1-10, New Dehli, India, October 12-17, 2014
@inproceedings{reiche2014hls,
author = {Reiche, Oliver and Schmid, Moritz and Hannig, Frank and Membarth, Richard and Teich, Jürgen},
booktitle = {Proceedings of the International Conference on Hardware/Software Codesign and System Synthesis (CODES+ISSS)},
venue = {New Dehli, India},
title = {{Code Generation from a Domain-specific Language for C-based HLS of Hardware Accelerators}},
pages = {17:1--17:10},
articleno = {17},
numpages = {10},
year = 2014,
month = oct,
date = {2014-10-12/2014-10-17},
doi = {10.1145/2656075.2656081},
organization = {ACM}
}
M. Roland T. Dahmen T. Tjardes R. Otchwemah P. Slusallek S. Diebels
Optimized patient-specific implants
Publication Type: Conference,
Proceedings of 11th World Congress on Computational Mechanics , Barcelona, Spain, 20.-25.Juni
K. Sons F. Klein J. Sutter P. Slusallek
shade.js: Adaptive Material Descriptions
Publication Type: Article,
Computer Graphics Forum, 33(7): 51-60, 2014
J. Sutter K. Sons P. Slusallek
Blast: A Binary Large Structured Transmission Format for the Web
Publication Type: Inproceedings,
Proceedings of the Nineteenth International ACM Conference on 3D Web Technologies (Web3D '14), pp. 45-52
I. Zinnikus S. Byelozyorov X. Cao M. Klusch C. Krauss A. Nonnengart T. Spieldenner S. Warwas P. Slusallek
A Collaborative Virtual Workspace for Factory Configuration and Evaluation
Publication Type: Article,
Collaborative Computing
2013
S. Byelozyorov D. Rubinstein V. Pegoraro P. Slusallek
An Open Modular Middleware for Interoperable Virtual Environments
Publication Type: Article,
Proceedings of the 12th IEEE International Conference on Cyberworlds
J. Doboš K. Sons D. Rubinstein P. Slusallek A. Steed
XML3DRepo: A REST API for Version Controlled 3D Assets on the Web
Publication Type: Inproceedings,
Proceedings of the 18th International Conference on 3D Web Technology (Web3D '13), pp. 47-55
J. Jankowski S. Ressler K. Sons Y. Jung J. Behr P. Slusallek
Declarative Integration of Interactive 3D Graphics into the World-Wide Web: Principles, Current Approaches, and Research Agenda
Publication Type: Inproceedings,
Proceedings of the 18th International Conference on 3D Web Technology (Web3D '13), pp. 39-45
F. Klein K. Sons D. Rubinstein P. Slusallek
XML3D and Xflow: Combining Declarative 3D for the Web with Generic Data Flows
Publication Type: Article,
Computer Graphics and Applications, IEEE, 33(5): 38-47, 2013
F. Klein D. Rubinstein K. Sons F. Einabadi S. Herhut P. Slusallek
Declarative AR and Image Processing on the Web with Xflow
Publication Type: Inproceedings,
Proceedings of the 18th International Conference on Web 3D Technology (Web3D '13), pp. 157-165
M. Maletta L. Marsalek B. Turonova P. Slusallek P. J. Peters
Electron cryo-tomography for observation of macromolecular changes induced by test compound within a cell
Publication Type: Poster,
Poster Presentation at 2nd Annual SEURAT-1 Meeting 2013, Lisbon, Portugal, March, 2013
S. Popov I. Georgiev P. Slusallek C. Dachsbacher
Adaptive Quantization Visibility Caching
Publication Type: Article,
Computer Graphics Forum, 32(2), 2013
S. Roland D. Cornelia P. Slusallek G. Mashuda
Grand Challenges: Material Models in Automotive
Publication Type: Article,
Workshop on Material Appearance Modeling (2013), Eds. H. Rushmeier and R. Klein
K. Sons G. Demme W. Herget P. Slusallek
Fortress City Saarlouis: Development of an interactive 3D City Model using Web Technologies
Publication Type: Inproceedings,
Proceedings of the CAA 2013 Conference Across Space and Time
K. Sons C. Schlinkmann F. Klein D. Rubinstein P. Slusallek
xml3d.js: Architecture of a Polyfill Implementation of XML3D
Publication Type: Inproceedings,
Software Engineering and Architectures for Realtime Interactive Systems (SEARIS), 2013 6th Workshop on (SEARIS), pp. 17-24
B. Turonova L. Marsalek T. Davidovic P. Slusallek
Progressive stochastic reconstruction technique for cryo electron tomography
Publication Type: Inproceedings,
SIGGRAPH Asia 2013 Posters (SA '13), pp. 11:1
2012
S. Byelozyorov R. Jochem V. Pegoraro P. Slusallek
From real cities to virtual worlds using an open modular architecture
Publication Type: Article,
The Visual Computer
T. Davidovic I. Georgiev P. Slusallek
Progressive Lightcuts for GPU
Publication Type: Article,
ACM SIGGRAPH 2012 Talks
T. Davidovic T. Engelhardt I. Georgiev P. Slusallek C. Dachsbacher
3D Rasterization: A Bridge between Rasterization and Ray Casting
Publication Type: Article,
Proceedings of the 2012 Graphics Interace Conference
H. Friedrich
Ray tracing techniques for computer games and isosurface visualization
Publication Type: Phdthesis,
I. Georgiev J. Krivanek S. Popov P. Slusallek
Importance Caching for Complex Illumination
Publication Type: Article,
Computer Graphics Forum, 31(2): 701-710, 2012
I. Georgiev J. Krivanek T. Davidovic P. Slusallek
Light Transport Simulation with Vertex Connection and Merging
Publication Type: Article,
ACM Transactions on Graphics (TOG), 31: XXX:1-XXX:10, 2012
R. Jochem M. Götz
Towards Interactive 3D City Models on the Web
Publication Type: Article,
International Journal of 3-D Information Modeling (IJ3DIM), 1(3): 26-36, 2012
J. Kalojanov M. Bokeloh M. Wand L. Guibas H. Seidel P. Slusallek
Microtiles: Extracting Building Blocks from Correspondences
Publication Type: Article,
Computer Graphics Forum, 31(5): 1597-1606, 2012
F. Klein K. Sons D. Rubinstein S. Byelozyorov S. John P. Slusallek
Xflow - Declarative Data Processing for the Web
Publication Type: Inproceedings,
Proceedings of the 17th International Conference on Web 3D Technology, pp. 37-45
A. Löffler L. Pica H. Hoffmann P. Slusallek
Multi-Display-Wände als skalierbare, immersive Stereo-Anzeigesysteme
Publication Type: Inproceedings,
9. Fachtagung "Digitales Engineering zum Planen, Testen und Betreiben technischer Systeme" (15. Fraunhofer IFF-Wissenschaftstage)
A. Löffler L. Pica H. Hoffmann P. Slusallek
Networked Displays for VR Applications: Display as a Service (DaaS)
Publication Type: Inproceedings,
Virtual Environments 2012: Proceedings of Joint Virtual Reality Conference of ICAT, EuroVR, and EGVE (JVRC)
J. Miroll A. Löffler J. Metzger P. Slusallek T. Herfet
Reverse Genlock for Synchronous Tiled Display Walls with Smart Internet Displays
Publication Type: Inproceedings,
Proceedings of the 2nd IEEE International Conference on Consumer Electronics (ICCE-Berlin)
S. Popov
Algorithms and data structures for interactive ray tracing on commodity hardware
Publication Type: Phdthesis,
2011
C. Brownlee V. Pegoraro S. Shankar P. S. McCormick C. D. Hansen
Physically-Based Interactive Flow Visualization Based on Schlieren and Interferometry Experimental Techniques
Publication Type: Article,
IEEE Transactions on Visualization and Computer Graphics, 17(11): 1574-1586, 2011
S. Byelozyorov V. Pegoraro P. Slusallek
An Open Modular Architecture for Effective Integration of Virtual Worlds in the Web
Publication Type: Inproceedings,
Proceedings of the 10th IEEE International Conference on Cyberworlds, pp. 46-53
T. Davidovic L. Marsalek P. Slusallek
Performance Considerations When Using a Dedicated Ray Traversal Engine
Publication Type: Inproceedings,
19th International Conference on Computer Graphics, Visualization and Computer Vision 2011 (WSCG 2011) Pilsen, pp. 65-72
I. Georgiev J. Krivanek P. Slusallek
Bidirectional Light Transport with Vertex Merging
Publication Type: Inproceedings,
SIGGRAPH Asia (technical sketches), pp. 27:1-27:2
M. Hapala T. Davidovic I. Wald V. Havran P. Slusallek
Efficient Stack-less BVH Traversal for Ray Tracing
Publication Type: Inproceedings,
Proceedings 27th Spring Conference on Computer Graphics (SCCG) 2011, pp. 29-34
J. Kalojanov M. Billeter P. Slusallek
Two-Level Grids for Ray Tracing on GPUs
Publication Type: Article,
Computer Graphics Forum
A. Löffler L. Marsalek H. Hoffmann P. Slusallek
Realistic Lighting Simulation for Interactive VR Applications
Publication Type: Inproceedings,
Virtual Environments 2011: Proceedings of Joint Virtual Reality Conference of euroVR and EGVE (JVRC), pp. 1-8
V. Pegoraro M. Schott P. Slusallek
A Mathematical Framework for Efficient Closed-Form Single Scattering
Publication Type: Inproceedings,
Proceedings of the 37th Graphics Interface Conference, pp. 151-158
V. Pegoraro P. Slusallek
On the Evaluation of the Complex-Valued Exponential Integral
Publication Type: Article,
Journal of Graphics, GPU, and Game Tools, 15(3): 183-198, 2011
M. Schott A. V. P. Grosset T. O. Martin V. Pegoraro S. T. Smith C. D. Hansen
Depth of Field Effects for Interactive Direct Volume Rendering
Publication Type: Article,
Computer Graphics Forum (Proceedings of the 13th Eurographics Symposium on Visualization), 30(3): 941-950, 2011
K. Sons P. Slusallek
XML3D Physics: Declarative Physics Simulation for the Web
Publication Type: Inproceedings,
Workshop on Virtual Reality Interaction and Physical Simulation VRIPHYS (2011), pp. 55-63
B. Turonova
Simultaneous Algebraic Reconstruction Technique for Electron Tomography using OpenCL
Publication Type: Mastersthesis,
M. Weier A. Hinkenjann G. Demme P. Slusallek
SILVA: System to Instantiate Large Vegetated Areas
Publication Type: Inproceedings,
Virtuelle und Erweiterte Realität, 8. Workshop der GI-Fachgruppe VR/AR, pp. 97-108
2010
S. Byelozyorov
Construction of Virtual Worlds with Web 2.0 Technology
Publication Type: Mastersthesis,
P. Danilewski S. Popov P. Slusallek
Binned SAH Kd-Tree Construction on a GPU
Publication Type: Techreport,
T. Davidovic J. Krivanek M. Hasan P. Slusallek K. Bala
Combining global and local virtual lights for detailed glossy illumination
Publication Type: Article,
ACM Transactions on Graphics (TOG), 29: 143:1-143:8, 2010
I. Georgiev P. Slusallek
Simple and Robust Iterative Importance Sampling of Virtual Point Lights
Publication Type: Inproceedings,
Proceedings of Eurographics 2010
R. Karrenberg D. Rubinstein P. Slusallek S. Hack
AnySL: Efficient and Portable Shading for Ray Tracing
Publication Type: Conference,
Proceedings of the Conference on High Performance Graphics (HPG), pp. 97-105, Saarbrücken, Germany, June 25-27, 2010
L. Marsalek I. Georgiev A. K. Dehof H. Lenhof P. Slusallek A. Hildebrandt
Real-Time Ray Tracing of Complex Molecular Scenes
Publication Type: Inproceedings,
14th International Conference on Information Visualisation (IV), pp. 239-245
L. Marsalek A. K. Dehof I. Georgiev D. Stöckel S. Nickels H. Lenhof P. Slusallek A. Hildebrandt
Real-Time Ray Tracing and Volume Rendering in Molecular Visualization
Publication Type: Poster,
Poster Presentation at
S. Nesbigall S. Warwas P. Kapahnke R. Schubotz M. Klusch K. Fischer P. Slusallek
Intelligent agents for semantic simulated realities - The ISReal platform
Publication Type: Unknown,
S. G. Parker J. Bigler A. Dietrich H. Friedrich J. Hoberock D. Luebke D. McAllister M. McGuire K. Morley A. Robinson M. Stich
OptiX: A General Purpose Ray Tracing Engine
Publication Type: Article,
ACM Transactions on Graphics (TOG)
V. Pegoraro M. Schott S. G. Parker
A Closed-Form Solution to Single Scattering for General Phase Functions and Light Distributions
Publication Type: Article,
Computer Graphics Forum (Proceedings of the 21st Eurographics Symposium on Rendering), 29(4): 1365-1374, 2010
M. Phillips A. K. Dehof I. Georgiev S. Nickels L. Marsalek H. Lenhof A. Hildebrandt P. Slusallek
Measuring Properties of Molecular Surfaces Using Ray Casting
Publication Type: Inproceedings,
Proceedings of 9th International Workshop on High Performance Computational Biology, pp. 1-7
M. Repplinger A. Löffler B. Schug P. Slusallek
SORA: a Service-Oriented Rendering Architecture
Publication Type: Inproceedings,
3rd Workshop on Software Engineering and Architectures for Realtime Interactive Systems (SEARIS@VR2010), pp. 25-30
K. Sons F. Klein D. Rubinstein S. Byelozyorov P. Slusallek
XML3D – Interactive 3D Graphics for the Web
Publication Type: Inproceedings,
Proceedings of the 15th International Conference on 3D Web Technology, pp. 175-184
2009
C. Dachsbacher P. Slusallek T. Davidovic T. Engelhart M. Philipps I. Georgiev
3D Rasterization -- Unifying Rasterization and Ray Casting
Publication Type: Techreport,
T. Davidovic L. Marsalek N. Maeding M. Kaltenbach P. Roth P. Slusallek
Ray Tracing Element for Cell/B.E.
Publication Type: Poster,
Poster Presentation at
A. Dehof I. Georgiev L. Marsalek D. Stöckel S. Nickels H. Lenhof P. Slusallek A. Hildebrandt
Real-time ray tracing of complex molecular scenes with BALLView and RTfact
Publication Type: Poster,
Poster Presentation at
A. K. Dehof L. Marsalek I. Georgiev D. Stöckel S. Nickels H. Lenhof P. Slusallek A. Hildebrandt
Interactive Real-Time Ray Tracing in Molecular Visualization
Publication Type: Poster,
Poster Presentation at
H. Hoffmann D. Rubinstein A. Löffler M. Repplinger P. Slusallek
Integration of Realtime Ray Tracing Into Interactive Virtual Reality Systems
Publication Type: Inproceedings,
Proceedings of the 2nd Sino-German Workshop Virtual Reality & Augmented Reality in Industry
H. Hoffmann D. Rubinstein A. Löffler P. Slusallek
Integration von Real-Time Raytracing in interaktive Virtual-Reality-Systeme
Publication Type: Inproceedings,
Digitales Engineering zum Planen, Testen und Betreiben technischer Systeme (12. Fraunhofer IFF Wissenschaftstage), pp. 343-352
J. Horacek L. Marsalek M. Horak J. Pelikan P. Slusallek
Segmentation of Femoral Head from CT after Femoral Neck Fracture
Publication Type: Inproceedings,
IAPR Conference on Machine Vision Applications (MVA), pp. 243-248
J. Kalojanov P. Slusallek
A Parallel Algorithm for Construction of Uniform Grids
Publication Type: Inproceedings,
Proceedings of High Performance Graphics 2009
A. Löffler M. Repplinger P. Slusallek
Verteiltes Rendering: Flexible Spezifikation und Konfiguration mittels Multimedia-Middleware
Publication Type: Inproceedings,
8. Paderborner Workshop Augmented & Virtual Reality in der Produktentstehung, pp. 79-94
L. Marsalek S. Nickels A. Dehof H. Lenhof P. Slusallek A. Hildebrandt
Real-Time Volume Ray Tracing For Bioinformatics Applications
Publication Type: Poster,
Poster Presentation at
S. Popov I. Georgiev R. Dimov P. Slusallek
Object Partitioning Considered Harmful: Space Subdivision for BVHs
Publication Type: Inproceedings,
HPG '09: Proceedings of the 1st ACM conference on High Performance Graphics, pp. 15-22
M. Repplinger A. Löffler P. Slusallek
ISReal: Advanced Computer Graphics Methods for Archaeology
Publication Type: Inproceedings,
Proceedings of Computer Application and Quantitative Methods in Archaeology 2009 (CAA 2009)
M. Repplinger A. Löffler M. Thielen P. Slusallek
A Flexible Adaptation Service for Distributed Rendering
Publication Type: Inproceedings,
Proceedings of 9th Eurographics Symposium on Parallel Graphics and Visualization 2009 (EGPGV '09), pp. 49-56
M. Repplinger M. Beyer P. Slusallek
Multimedia Processing on Many-Core Technologies Using Distributed Multimedia Middleware
Publication Type: Inproceedings,
Proceedings of the 13th IASTED International Conference on Internet and Multimedia Systems and Applications (IMSA '09)
M. Repplinger A. Löffler D. Rubinstein P. Slusallek
DRONE: a Flexible Framework for Distributed Rendering and Display
Publication Type: Inproceedings,
Proceedings of the 7th International Conference on Visual Computing (ISVC09), Part I, pp. 975-986
M. Repplinger P. Slusallek
Stream Processing on GPUs Using Distributed Multimedia Middleware
Publication Type: Inproceedings,
Proceedings of the 8th International Conference on Parallel Processing and Applied Mathematics - PPAM 2009
M. Repplinger A. Löffler B. Schug P. Slusallek
Extending X3D for Distributed Multimedia Processing and Control
Publication Type: Inproceedings,
Proceedings of the 14th International Conference on 3D Web Technology 2009 (Web3D Symposium '09), pp. 61-69
D. Rubinstein I. Georgiev B. Schug P. Slusallek
RTSG: Ray Tracing for X3D via a Flexible Rendering Framework
Publication Type: Inproceedings,
Proceedings of the 14th International Conference on 3D Web Technology 2009 (Web3D Symposium '09), pp. 43-50
M. Stich H. Friedrich A. Dietrich
Spatial Splits in Bounding Volume Hierarchies
Publication Type: Inproceedings,
Proceeding of High Performance Graphics
2008
I. Georgiev P. Slusallek
RTfact: Generic Concepts for Flexible and High Performance Ray Tracing
Publication Type: Inproceedings,
Proceedings of the IEEE/EG Symposium on Interactive Ray Tracing 2008, pp. pp. 115-122
I. Georgiev D. Rubinstein H. Hoffmann P. Slusallek
Real Time Ray Tracing on Many-Core-Hardware
Publication Type: Inproceedings,
Proceedings of the 5th INTUITION Conference on Virtual Reality
D. Kasik A. Dietrich E. Gobbetti F. Marton D. Manocha P. Slusallek A. Stephens S. Yoon
Massive Model Visualization Techniques
Publication Type: Misc,
M. Lohse F. Winter M. Repplinger P. Slusallek
Network-Integrated Multimedia Middleware (NMM)
Publication Type: Inproceedings,
Proceedings of ACM Multimedia 2008 (ACM MM 2008)
L. Marsalek A. Hauber P. Slusallek
High-speed volume ray casting with CUDA
Publication Type: Poster,
Poster Presentation at
S. Yoon M. Agus A. Dietrich E. Gobbetti F. Marton R. Pajarola P. Slusallek
Interactive Massive Model Rendering
Publication Type: Misc,
2007
T. Davidovic M. Havlan M. Novotny J. Schmidt P. Bezpalec
Framework for Research of ECDSA
Publication Type: Misc,
A. Dietrich P. Slusallek
Adaptive Spatial Sample Caching
Publication Type: Inproceedings,
Proceedings of the IEEE/EG Symposium on Interactive Ray Tracing 2007, pp. 141-147
A. Dietrich G. Marmitt P. Slusallek
Trillion Triangle Terrain
Publication Type: Article,
Computer Graphics Forum, 26(1): 129-130, 2007
A. Dietrich E. Gobbetti S. Yoon
Massive Model Rendering Techniques
Publication Type: Article,
IEEE Computer Graphics and Applications, 27(6): 20-34, 2007
A. Dietrich A. Stephens I. Wald
Exploring a Boeing 777: Ray Tracing Large-Scale CAD Data
Publication Type: Article,
IEEE Computer Graphics and Applications, 27(6): 36-46, 2007
H. Friedrich I. Wald J. Günther G. Marmitt P. Slusallek
Interactive Iso-Surface Ray Tracing of Massive Volumetric Data Sets
Publication Type: Inproceedings,
Proceedings of the 2007 Eurographics Symposium on Parallel Graphics and Visualization
J. Günther S. Popov H. Seidel P. Slusallek
Realtime Ray Tracing on GPU with BVH-based Packet Traversal
Publication Type: Inproceedings,
Proceedings of the IEEE/Eurographics Symposium on Interactive Ray Tracing 2007, pp. 113-118
D. Kasik B. Brüderlin W. Correa A. Dietrich E. Gobbetti D. Manocha F. Marton I. Quilez P. Slusallek A. Stephens S. Yoon
State of the Art in Massive Model Visualization
Publication Type: Misc,
S. Popov J. Günther H. Seidel P. Slusallek
Stackless KD-Tree Traversal for High Performance GPU Ray Tracing
Publication Type: Article,
Computer Graphics Forum, 26(3), 2007
S. Popov J. Güenther H. Seidel P. Slusallek
Stackless KD-Tree Traversal for High Performance GPU Ray Tracing
Publication Type: Techreport,
I. Wald W. R Mark J. Günther S. Boulos T. Ize W. Hunt S. G. Parker P. Shirley
State of the Art in Ray Tracing Animated Scenes
Publication Type: Inproceedings,
Eurographics 2007 State of the Art Reports
2006
C. Benthin I. Wald M. Scherbaum H. Friedrich
Ray Tracing on the CELL Processor
Publication Type: Inproceedings,
Proceedings of the 2006 IEEE Symposium on Interactive Ray Tracing, pp. 15-23
C. Benthin I. Wald P. Slusallek
Techniques for Interactive Ray Tracing of Bèzier Surfaces
Publication Type: Article,
Journal of Graphics Tools, 11(2): 1-16, 2006
T. Davidovic M. Havlan M. Novotny J. Schmidt
Implementation of ECDSA in Combo6X Card
Publication Type: Misc,
A. Dietrich I. Wald H. Schmidt K. Sons P. Slusallek
Realtime Ray Tracing for Advanced Visualization in the Aerospace Industry
Publication Type: Inproceedings,
Proceedings of the 5th Paderborner Workshop Augmented & Virtual Reality in der Produktentstehung
A. Dietrich G. Marmitt P. Slusallek
Terrain Guided Multi-Level Instancing of Highly Complex Plant Populations
Publication Type: Inproceedings,
Proceedings of the 2006 IEEE Symposium on Interactive Ray Tracing, pp. 169-176
A. Dietrich J. Schmittler P. Slusallek
World-Space Sample Caching for Efficient Ray Tracing of Highly Complex Scenes
Publication Type: Techreport,
H. Friedrich J. Günther A. Dietrich M. Scherbaum H. Seidel P. Slusallek
Exploring the Use of Ray Tracing for Future Games
Publication Type: Inproceedings,
Proceedings of ACM SIGGRAPH Video Game Symposium
B. Fuchshumer M. Kretz M. Repplinger M. Lohse
Phonon and NMM -- Multimedia Architectures for the Desktop and Beyond
Publication Type: Misc,
J. Günther H. Friedrich H. Seidel P. Slusallek
Interactive Ray Tracing of Skinned Animations
Publication Type: Article,
The Visual Computer, 22(9): 785-792, 2006
J. Günther H. Friedrich I. Wald H. Seidel P. Slusallek
Ray Tracing Animated Scenes using Motion Decomposition
Publication Type: Article,
Computer Graphics Forum, 25(3): 517-525, 2006
D. Kasik D. Manocha S. Yoon A. Stephens B. Brüderlin P. Slusallek A. Dietrich E. Gobbetti F. Marton W. Correa I. Quilez
State of the Art in Massive Model Visualization
Publication Type: Misc,
G. Marmitt R. Brauchle H. Friedrich P. Slusallek
Accelerated and Extended Building of Implicit kd-Trees for Volume Ray Tracing
Publication Type: Inproceedings,
Proceedings of 11th International Fall Workshop - Vision, Modeling, and Visualization (VMV) 2006, pp. 317-324
G. Marmitt P. Slusallek
Fast Ray Traversal of Tetrahedral and Hexahedral Meshes for Direct Volume Rendering
Publication Type: Inproceedings,
Proceedings of Eurographics/IEEE-VGTC Symposium on Visualization (EuroVIS)
G. Marmitt H. Friedrich P. Slusallek
Interactive Volume Rendering with Ray Tracing
Publication Type: Inproceedings,
Eurographics State of the Art Reports
S. Popov J. Günther H. Seidel P. Slusallek
Experiences with Streaming Construction of SAH KD-Trees
Publication Type: Inproceedings,
Proceedings of the 2006 IEEE Symposium on Interactive Ray Tracing, pp. 89-94
S. Popov
Stackless KD-Tree Traversal for Ray Tracing on Graphics Hardware
Publication Type: Mastersthesis,
J. Schmittler
SaarCOR - A Hardware-Architecture for Realtime Ray Tracing
Publication Type: Phdthesis,
I. Wald A. Dietrich C. Benthin A. Efremov T. Dahmen J. Günther V. Havran H. Seidel P. Slusallek
Applying Ray Tracing for Virtual Reality and Industrial Design
Publication Type: Inproceedings,
Proceedings of the 2006 IEEE Symposium on Interactive Ray Tracing, pp. 177-185
S. Woop G. Marmitt P. Slusallek
B-KD Trees for Hardware Accelerated Ray Tracing of Dynamic Scenes
Publication Type: Inproceedings,
Proceedings of Graphics Hardware
S. Woop
DRPU: A Programmable Hardware Architecture for Real-time Ray Tracing ofCoherent Dynamic Scenes
Publication Type: Techreport,
S. Woop E. Brunvand P. Slusallek
Estimating Performance of a Ray-Tracing ASIC Design
Publication Type: Conference,
Proceedings of IEEE Symposium on Interactive Ray Tracing 2006, pp. 7-14, Salt Lake City, UT, USA, September 18-20, 2006
2005
A. Dietrich C. Colditz O. Deussen P. Slusallek
Realistic and Interactive Visualization of High-Density Plant Ecosystems
Publication Type: Inproceedings,
Natural Phenomena 2005, Proceedings of the Eurographics Workshop on Natural Phenomena, pp. 73-81
A. Dietrich I. Wald P. Slusallek
Large-Scale CAD Model Visualization on a Scalable Shared-Memory Architecture
Publication Type: Inproceedings,
Proceedings of 10th International Fall Workshop - Vision, Modeling, and Visualization (VMV) 2005, pp. 303-310
A. Löffler D. Wallach
3D User Interfaces as a Challenge for Cognitive Science
Publication Type: Inproceedings,
Proceedings of KogWis '05: 7. Fachtagung Gesellschaft für Kognitionswissenschaft , pp. 125-130
M. Lohse
Network-Integrated Multimedia Middleware, Services, and Applications
Publication Type: Phdthesis,
M. Lohse M. Repplinger P. Slusallek
Dynamic Media Routing in Multi-User Home Entertainment Systems
Publication Type: Inproceedings,
Proceedings of The Eleventh International Conference on Distributed Multimedia Systems (DMS), pp. 271-276
M. Lohse P. Slusallek
Towards Automatic Setup of Distributed Multimedia Applications
Publication Type: Inproceedings,
Proceedings of The 9th IASTED International Conference on Internet and Multimedia Systems and Applications (IMSA), pp. 359-364
G. Marmitt P. Slusallek
Fast Ray Traversal of Unstructured Volume Data using Plucker Tests
Publication Type: Techreport,
G. Marmitt H. Friedrich P. Slusallek
Recent Advancements in Ray-Tracing based Volume Rendering Techniques
Publication Type: Inproceedings,
Proceedings of 10th International Fall Workshop - Vision, Modeling, and Visualization (VMV) 2005, pp. 131-138
A. Pomi
Interactive Mixed Reality Rendering in a Distributed Ray Tracing Framework
Publication Type: Phdthesis,
M. Repplinger F. Winter M. Lohse P. Slusallek
Parallel Bindings in Distributed Multimedia Systems
Publication Type: Inproceedings,
Proceedings of the 25th IEEE International Conference on Distributed Computing Systems Workshops (ICDCS 2005), pp. 714-720
I. Wald H. Friedrich G. Marmitt P. Slusallek H. Seidel
Faster Isosurface Ray Tracing Using Implicit KD-Trees
Publication Type: Article,
IEEE Transactions on Visualization and Computer Graphics, 11(5): 562-572, 2005
I. Wald C. Benthin A. Efremov T. Dahmen J. Günther A. Dietrich V. Havran P. Slusallek H. Seidel
A Ray Tracing based Virtual Reality Framework for Industrial Design
Publication Type: Techreport,
S. Woop J. Schmittler P. Slusallek
RPU: A Programmable Ray Processing Unit for Realtime Ray Tracing
Publication Type: Inproceedings,
Proceedings of ACM SIGGRAPH 2005
2004
C. Benthin I. Wald P. Slusallek
Interactive Ray Tracing of Free-Form Surfaces
Publication Type: Inproceedings,
Proceedings of Afrigraph 2004
A. Dietrich I. Wald P. Slusallek
Interactive Visualization of Exceptionally Complex Industrial Datasets
Publication Type: Inproceedings,
ACM SIGGRAPH 2004, Sketches and Applications
A. Dietrich I. Wald P. Slusallek
Interaktive Visualisierung eines hoch komplexen Boeing 777 Modells (Cover Image)
Publication Type: Article,
Informatik Spektrum, 27(4): 394-394, 2004
A. Dietrich I. Wald P. Slusallek
Interaktive Darstellung hoch detaillierter Landschaftsszenen (Cover Image)
Publication Type: Article,
Informatik Spektrum, 27(5): 480-480, 2004
A. Dietrich I. Wald M. Wagner P. Slusallek
VRML Scene Graphs on an Interactive Ray Tracing Engine
Publication Type: Inproceedings,
Proceedings of IEEE VR 2004, pp. 109-116
N. Fritz P. Lucas P. Slusallek
CGiS, a new Language for Data-Parallel GPU Programming
Publication Type: Inproceedings,
Vision, Modelling, and Visualization 2004 (VMV) , November 16-18, Stanford (CA), USA, pp. 241-248
J. Günther I. Wald P. Slusallek
Realtime Caustics using Distributed Photon Mapping
Publication Type: Inproceedings,
Rendering Techniques 2004, Proceedings of the Eurographics Symposium on Rendering, pp. 111-121
G. Marmitt A. Kleer I. Wald H. Friedrich P. Slusallek
Fast and Accurate Ray-Voxel Intersection Techniques for Iso-Surface Ray Tracing
Publication Type: Inproceedings,
Vision, Modelling, and Visualization 2004 (VMV) , November 16-18, Stanford (CA), USA
A. Pomi P. Slusallek
Interactive Mixed Reality Rendering in a Distributed Ray Tracing Framework
Publication Type: Inproceedings,
IEEE and ACM International Symposium on Mixed and Augmented Reality ISMAR 2004, Student Colloquium
A. Pomi S. Hoffmann P. Slusallek
Interactive In-Shader Image-Based Visual Hull Reconstruction and Compositing of Actors in a Distributed Ray Tracing Framework
Publication Type: Inproceedings,
1. Workshop VR/AR, Chemnitz, Germany
M. Repplinger F. Winter M. Lohse P. Slusallek
Parallel Bindings in Distributed Multimedia Systems
Publication Type: Techreport,
J. Schmittler S. Woop D. Wagner W. J. Paul P. Slusallek
Realtime Ray Tracing of Dynamic Scenes on an FPGA Chip
Publication Type: Inproceedings,
Proceedings of Graphics Hardware, pp. 95-106
J. Schmittler D. Pohl T. Dahmen C. Vogelgesang P. Slusallek
Ray Tracing for Current and Future Games
Publication Type: Inproceedings,
Proceedings of 34. Jahrestagung der Gesellschaft für Informatik
I. Wald A. Dietrich P. Slusallek
An Interactive Out-of-Core Rendering Framework for Visualizing Massively Complex Models
Publication Type: Inproceedings,
Rendering Techniques 2004, Proceedings of the Eurographics Symposium on Rendering, pp. 81-92
I. Wald J. Günther P. Slusallek
Balancing Considered Harmful -- Faster Photon Mapping using the Voxel Volume Heuristic
Publication Type: Inproceedings,
Computer Graphics Forum
I. Wald A. Dietrich P. Slusallek
Afrigraph 2004 Course on "State of the Art in Massive Model Visualization"
Publication Type: Misc,
2003
C. Benthin I. Wald P. Slusallek
A Scalable Approach to Interactive Global Illumination
Publication Type: Article,
Computer Graphics Forum, 22(3): 621-630, 2003
A. Dietrich I. Wald C. Benthin P. Slusallek
The OpenRT Application Programming Interface - Towards A Common API for Interactive Ray Tracing
Publication Type: Inproceedings,
Proceedings of the 2003 OpenSG Symposium, pp. 23-31
M. Lohse P. Slusallek
Middleware Support for Seamless Multimedia Home Entertainment for Mobile Users and Heterogeneous Environments
Publication Type: Inproceedings,
Proceedings of The 7th IASTED International Conference on Internet and Multimedia Systems and Applications (IMSA), pp. 217-222
M. Lohse M. Repplinger P. Slusallek
Session Sharing as Middleware Service for Distributed Multimedia Applications
Publication Type: Inproceedings,
Interactive Multimedia on Next Generation Networks, Proceedings of First International Workshop on Multimedia Interactive Protocols and Systems, MIPS 2003 (Lecture Notes in Computer Science ), pp. 258-269
M. Lohse M. Repplinger P. Slusallek
Dynamic Distributed Multimedia: Seamless Sharing and Reconfiguration of Multimedia Flow Graphs
Publication Type: Inproceedings,
Proceedings of the 2nd International Conference on Mobile and Ubiquitous Multimedia (MUM 2003), pp. 89-95
M. Lohse
Ein Knoten für alle Fälle, NMM - Vernetztes Multimedia Home Entertainment mit Linux
Publication Type: Misc,
A. Pomi G. Marmitt I. Wald P. Slusallek
Streaming Video Textures for Mixed Reality Applications in Interactive Ray Tracing Environments
Publication Type: Inproceedings,
Virtual Reality, Modelling and Visualization 2003 (VMV) , November 19-21, Munich, Germany
J. Schmittler A. Leidinger P. Slusallek
A Virtual Memory Architecture for Real-Time Ray Tracing Hardware
Publication Type: Inproceedings,
Computer & Graphics, pp. 0097-8493
I. Wald C. Benthin P. Slusallek
Distributed Interactive Ray Tracing of Dynamic Scenes
Publication Type: Inproceedings,
Proceedings of the IEEE Symposium on Parallel and Large-Data Visualization and Graphics (PVG)
I. Wald C. Benthin A. Dietrich P. Slusallek
Interactive Distributed Ray Tracing on Commodity PC Clusters -- State of the Art and Practical Applications
Publication Type: Article,
Lecture Notes on Computer Science, 2790: 499-508, 2003
I. Wald C. Benthin P. Slusallek
Interactive Global Illumination in Complex and Highly Occluded Environments
Publication Type: Inproceedings,
Proceedings of the 14th Eurographics Workshop on Rendering
I. Wald T. J. Purcell J. Schmittler C. Benthin P. Slusallek
Realtime Ray Tracing and its use for Interactive Global Illumination
Publication Type: Inproceedings,
Eurographics State of the Art Reports
I. Wald C. Benthin P. Slusallek
Afrigraph 2003 Course on "Advanced Interactive Ray Tracing and Interactive Global Illumination"
Publication Type: Misc,
2002
C. Benthin I. Wald T. Dahmen P. Slusallek
Interactive Headlight Simulation -- A Case Study for Distributed Interactive Ray Tracing
Publication Type: Inproceedings,
Proceedings of EUROGRAPHICS Workshop on Parallel Graphics and Visualization (PGV), pp. 81-88
M. Lohse P. Slusallek
An Open Platform for Multimedia Entertainment Systems
Publication Type: Inproceedings,
EUROPRIX Scholars Conference at MindTrek Media Week
M. Lohse M. Repplinger P. Slusallek
An Open Middleware Architecture for Network-Integrated Multimedia
Publication Type: Inproceedings,
Protocols and Systems for Interactive Distributed Multimedia Systems, Joint International Workshops on Interactive Distributed Multimedia Systems and Protocols for Multimedia Systems, IDMS/PROMS 2002, Proceedings (Lecture Notes in Computer Science), pp. 327-338
J. Schmittler I. Wald P. Slusallek
SaarCOR - A Hardware Architecture For Ray Tracing
Publication Type: Inproceedings,
Proceedings of the conference on Graphics Hardware 2002, pp. 27-36
P. Slusallek I. Wald
Interaktive Beleuchtungssimulation und Bildsynthese mit Ray-Tracing - Effiziente Software schlägt Spezial-Hardware
Publication Type: Unknown,
I. Wald C. Benthin P. Slusallek
A Simple and Practical Method for Interactive Ray Tracing of Dynamic Scenes
Publication Type: Techreport,
I. Wald T. Kollig C. Benthin A. Keller P. Slusallek
Interactive Global Illumination using Fast Ray Tracing
Publication Type: Inproceedings,
Proceedings of the 13th EUROGRAPHICS Workshop on Rendering
I. Wald T. Kollig C. Benthin A. Keller P. Slusallek
Interactive Global Illumination
Publication Type: Techreport,
I. Wald C. Benthin P. Slusallek
OpenRT -- A Flexible and Scalable Rendering Engine for Interactive 3D Graphics
Publication Type: Techreport,
2001
M. Lohse P. Slusallek P. Wambach
Extended Format Definition and Quality-driven Format Negotiation in Multimedia Systems
Publication Type: Inproceedings,
Multimedia 2001 -- Proceedings of the Eurographics Workshop, pp. 65-74
I. Wald P. Slusallek C. Benthin
Interactive Distributed Ray Tracing of Highly Complex Models
Publication Type: Inproceedings,
Rendering Techniques 2001 (Proceedings of the 12th EUROGRAPHICS Workshop on Rendering, pp. 277-288
I. Wald C. Benthin M. Wagner P. Slusallek
Interactive Rendering with Coherent Ray Tracing
Publication Type: Inproceedings,
Com\-pu\-ter Graphics Forum (Proceedings of EUROGRAPHICS 2001
I. Wald P. Slusallek
State-of-the-Art in Interactive Ray-Tracing
Publication Type: Article,
State of the Art Reports, EUROGRAPHICS 2001
2000
X. Chen J. Davis P. Slusallek
Wide Area Camera Calibration Using Virtual Calibration
Publication Type: Inproceedings,
Computer Vision and Pattern Recognition, pp. 520-527
A. Keller I. Wald
Efficient Importance Sampling Techniques for the Photon Map
Publication Type: Inproceedings,
Vision Modelling and Visualization 2000, pp. 271-279
A. Keller I. Wald
Efficient Importance Sampling Techniques for the Photon Map
Publication Type: Inproceedings,
Vision Modelling and Visualization 2000, pp. 271-279
1999
P. Kipfer P. Slusallek
Transparent Distributed Processing for Rendering
Publication Type: Article,
Parallel Visualization and Graphics Symposium
1998
S. Campagna P. Slusallek H. Seidel
Ray Tracing of Spline Surfaces: Bezier Clipping, Chebyshev Boxing, and Bounding Volume Hierarchy - A Critical Comparison with New Results
Publication Type: Article,
The Visual Computer
W. Heidrich J. Kautz P. Slusallek H. Seidel
Canned Lightsources
Publication Type: Inproceedings,
Rendering Techniques '98 (Proc. 9th EUROGRAPHICS Workshop on Rendering)
W. Heidrich P. Slusallek H. Seidel
Sampling Procedural Shaders Using Affine Arithmetic
Publication Type: Article,
ACM Transactions on Graphics (TOG)
J. Loos P. Slusallek H. Seidel
Using Wavefront Tracing for the Visualization and Optimization of Progressive Lenses
Publication Type: Inproceedings,
Computer Graphics Forum
S. Röttger W. Heidrich P. Slusallek H. Seidel
Real-Time Generation of Continuous Levels of Detail for Height Fields
Publication Type: Inproceedings,
Proc. WSCG '98
P. Slusallek M. Stamminger W. Heidrich J. Popp H. Seidel
Composite Lighting Simulations with Lighting Network
Publication Type: Article,
IEEE Computer Graphics and Applications, 18(2): 22-31, 1998
P. Slusallek M. Stamminger H. Seidel
Lighting Networks - A New Approach for Designing Lighting Algorithms
Publication Type: Conference,
Graphics Interface '98
P. Slusallek W. Heidrich H. Seidel
Radiance Maps: An Image-Based Approach to Global Illumination
Publication Type: Conference,
SIGGRAPH '98
M. Stamminger H. Schirmacher P. Slusallek H. Seidel
Getting Rid of Links in Hierarchical Radiosity
Publication Type: Inproceedings,
Computer Graphics Forum
M. Stamminger P. Slusallek H. Seidel
Bounded Clustering - Finding Good Bounds on Clustered Light Transport
Publication Type: Conference,
Pacific Graphics
M. Stamminger P. Slusallek H. Seidel
Three Point Clustering for Radiance Computations
Publication Type: Inproceedings,
Rendering Techniques '98 (Proc. 9th EUROGRAPHICS Workshop on Rendering '98), pp. 211-222
1997
W. Heidrich P. Slusallek H. Seidel
An Image-Based Model for Realistic Lens Systems in Interactive Computer Graphics
Publication Type: Inproceedings,
Proc. Graphics Interface '97
H. Seidel P. Slusallek M. Stamminger
Global Illumination Computations with Hierarchical Finite Element Methods
Publication Type: Inproceedings,
Proc. Mathematical Methods for Curves and Surfaces II, pp. 445-460
P. Slusallek
Photo-Realistic Rendering - Recent Trends and Developments
Publication Type: Techreport,
P. Slusallek M. Stamminger H. Seidel
Hierarchical Techniques for Global Illumination Computations - Recent Trends and Developments
Publication Type: Inproceedings,
Proc. Pacific Graphics, pp. 80-89
P. Slusallek M. Stamminger H. Seidel
Hierarchical Techniques for Global Illumination Computations
Publication Type: Inproceedings,
Proc. VisMath '97
M. Stamminger P. Slusallek H. Seidel
A Comparison of Different Refiners for Hierarchical Radiosity
Publication Type: Inproceedings,
Proc. 3D Image Analysis and Synthesis '97, pp. 27-34, infix
M. Stamminger W. Nitsch P. Slusallek H. Seidel
Isotropic Clustering for Hierarchical Radiosity - Implementation and Experiences
Publication Type: Inproceedings,
Proc. 5th International Conference in Central Europe on Computer Graphics and Visualization, pp. 534-542
M. Stamminger P. Slusallek H. Seidel
Bounded Radiosity - Illumination on General Surfaces and Clusters
Publication Type: Inproceedings,
Computer Graphics Forum, pp. 300-317
M. Stamminger P. Slusallek H. Seidel
Decoupling Propagation and Reflection for Radiance Computations
Publication Type: Inproceedings,
Proc. Graphicon '97, pp. 51-58
1996
P. Slusallek J. Paul F. Sillion
Using Realistic Lighting in Modern Graphics Applications
Publication Type: Techreport,
P. Slusallek R. Klein A. Kolb G. Greiner
Object-Oriented and Mixed Programming Paradigms
Publication Type: Inbook,
P. Slusallek H. Seidel
Towards an Open Rendering Kernel for Image Synthesis
Publication Type: Inproceedings,
Proc. 7th EUROGRAPHICS Workshop on Rendering '96, pp. 51-60
1995
S. Gortler M. Cohen P. Slusallek
Radiosity and Relaxation Methods
Publication Type: Article,
IEEE Comuter Graphics & Applications
W. Heidrich P. Slusallek
Automatic Generation of Tcl Bindings for C and C++ Libraries
Publication Type: Techreport,
P. Slusallek T. Pflaum H. Seidel
Using Procedural RenderMan Shaders for Global Illumination
Publication Type: Inproceedings,
Computer Graphics Forum (Proc. EUROGRAPHICS '95), pp. 311-324
P. Slusallek H. Seidel
Object-Oriented Design for Image Synthesis
Publication Type: Inproceedings,
5th EUROGRAPHICS Workshop on Programming Paradigms for Graphics, pp. 285-296
P. Slusallek M. Schröder M. Stamminger H. Seidel
Smart Links and Efficient Reconstruction for Wavelet Radiosity
Publication Type: Inproceedings,
Rendering Techniques '95 (Proc. 6th EUROGRAPHICS Workshop on Rendering), pp. 251-263
P. Slusallek H. Seidel
Vision: An Architecture for Global Illumination Calculations
Publication Type: Article,
IEEE Transactions on Visualization and Computer Graphics, 1(1): 77-96, 1995
M. Stamminger P. Slusallek H. Seidel
Interactive Walkthroughs and Higher Order Global Illumination
Publication Type: Article,
Modeling, Virtual Worlds, Distributed Graphics
1994
W. Heidrich P. Slusallek H. Seidel
Using C++ Class Libraries from an Interpreted Language
Publication Type: Conference,
Technology of Object-Oriented Languages and Systems, pp. 397-408
P. Slusallek T. Pflaum H. Seidel
Implementing RenderMan - Practice, Problems, and Enhancements
Publication Type: Inproceedings,
Computer Graphics Forum (Proc. EUROGRAPHICS '94), pp. 443-454
P. Slusallek R. Klein A. Kolb G. Greiner
Curves and Surfaces in Geometric Design
Publication Type: Inbook,
1993
G. Greiner W. Heidrich P. Slusallek
Blockwise Refinement - A New Method for Solving the Radiosity Problem
Publication Type: Inproceedings,
Rendering Techniques '93 (Proc. 4th EUROGRAPHICS Workshop on Rendering), pp. 233-245
1992
R. Klein P. Slusallek
An Object-Oriented Framework ofr Curves and Surfaces
Publication Type: Inproceedings,
Curves and Surfaces in Computer Vision and Graphics III (Proc. SPIE 1830), pp. 284-295
1990
P. Slusallek H. Seidel
TRIMO - A Workstation-Based Interactive System for the Generation, Manipulation, and Display of Surfaces Over Arbitrary Topological Meshes
Publication Type: Inproceedings,
Proc. EUROGRAPHICS '90, pp. 147-158

© Lehrstuhl Computer Graphik, Universität des Saarlandes, 1999-2024.